CUDA C编程
源码:https://www.wiley.com/en-us/Professional+CUDA+C+Programming-p-9781118739327
目录
- 目录
- 第1章 基于CUDA的异构并行计算
- 第2章 CUDA编程模型
- 第3章 CUDA执行模型
- 第4章 全局内存
- 第5章 共享内存和常量内存
- 第6章 流和并发
- 第7章 调整指令级原语
- 第8章 GPU加速库和OpenACC
- 第9章 多GPU编程
- 第10章 程序实现的注意事项
第1章 基于CUDA的异构并行计算
高性能计算的关键部分是中央处理单元(CPU),通常被称为计算机的核心。在早期的计算机中,一个芯片上只有一个CPU,这种结构被称为单核处理器。现在,芯片设计的 趋势是将多个核心集成到一个单一的处理器上,以在体系结构级别支持并行性,这种形式通常被称为多核处理器。因此,并行程序设计可以看作是将一个问题的计算分配给可用的核心以实现并行的过程。
1.1 并行计算
1.1.1 串行编程和并行编程
一个程序应包含两个基本的组成部分:指令和数据。当一个计算问题被划分成许多小的计算单元后,每个计算单元都是一个任务。在一个任务中,单独的指令负责处理输入和调用一个函数并产生输出。当一个指令处理前一个指令产生的数据时,就有了数据相关性的概念。
1.1.2 并行性
在应用程序中有两种基本的并行类型。
- 任务并行,当许多任务或函数可以独立地、大规模地并行执行时,这就是任务并行。任务并行的重点在于利用多核系统对任务进行分配。
- 数据并行,当可以同时处理许多数据时,这就是数据并行。数据并行的重点在于利用多核系统对数据进行分配。
数据并行程序设计的第一步是把数据依据线程进行划分,以使每个线程处理一部分数据。通常来说,有两种方法可以对数据进行划分:块划分(block partitioning)和周期划分(cyclic partitioning)。
- 在块划分中,每个线程作用于一部分数据,通常这些数据具有相同大小。一组连续的数据被分到一个块内。每个数据块以任意次序被安排给一个线程,线程通常在同一时间只处理一个数据块。
- 在周期划分中,每个线程作用于数据的多部分。更少的数据被分到一个块内。相邻的线程处理相邻的数据块,每个线程可以处理多个数据块。为一个待处理的线程选择一个新的块,就意味着要跳过和现有线程一样多的数据块。
1.1.3 计算机架构
弗林分类法(Flynn’s Taxonomy),它根据指令和数据进入CPU的方式,将计算机架构分为4种不同的类型。
- 单指令单数据(SISD),一种串行架构。在这种计算机上只有一个核心。在任何时间点上只有一个指令流在处理一个数据流。
- 单指令多数据(SIMD),一种并行架构类型。在这种计算机上有多个核心。在任何时间点上所有的核心只有一个指令流处理不同的数据流。
- 多指令单数据(MISD),每个核心通过使用多个指令流处理同一个数据流
- 多指令多数据(MIMD),一种并行架构,在这种架构中,多个核心使用多个指令流来异步处理多个数据流,从而实现空间上的并行性。许多 MIMD 架构还包括 SIMD 执行的子组件。
架构层次优化方向:
- 降低延迟,延迟是一个操作从开始到完成所需要的时间,常用微秒来表示。
- 提高带宽,带宽是单位时间内可处理的数据量,通常表示为MB/s或GB/s。
- 提高吞吐量,吞吐量是单位时间内成功处理的运算数量,通常表示为gflops(即每秒十亿次的浮点运算数量),特别是在重点使用浮点计算的科学计算领域经常用到。
延迟用来衡量完成一次操作的时间,而吞吐量用来衡量在给定的单位时间内处理的操作量。
根据内存组织方式进行进一步划分,一般可以分成下面两种类型。
- 分布式内存的多节点系统,多节点系统中,大型计算引擎是由许多网络连接的处理器构成的。每个处理器有自己的本地内存,而且处理器之间可以通过网络进行通信。这种系统常被称作
集群。 - 共享内存的多处理器系统,多处理器架构的大小通常是从双处理器到几十个或几百个处理器之间。这些处理器要么是与同一个物理内存相关联,要么共用一个低延迟的链路(如PCI-Express或PCIe)。
众核(many-core)通常是指有很多核心(几十或几百个)的多核架构。近年来,计算机架构正在从多核转向众核。
GPU代表了一种众核架构,包括:多线程、MIMD(多指令多数据)、SIMD(单指令多数据),以及指令级并行。NVIDIA公司称这种架构为SIMT(单指令多线程)。
- CPU核心比较重,用来处理非常复杂的控制逻辑,以优化串行程序执行。
- GPU核心较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。
1.2 异构计算
CPU和GPU是两个独立的处理器,它们通过单个计算节点中的PCI-Express总线相连。在这种典型的架构中,GPU指的是离散的设备从同构系统到异构系统的转变是高性能计算史上的一个里程碑。同构计算使用的是同一架构下的一个或多个处理器来执行一个应用。而异构计算则使用一个处理器架构来执行一个应用,为任务选择适合它的架构,使其最终对性能有所改进。
1.2.1 异构架构
一个典型的异构计算节点包括两个多核CPU插槽和两个或更多个的众核GPU。GPU不是一个独立运行的平台而是CPU的协处理器。一个异构应用包括两个部分。
- 主机代码
- 设备代码
主机代码在CPU上运行,设备代码在GPU上运行。异构平台上执行的应用通常由CPU初始化。在设备端加载计算密集型任务之前,CPU代码负责管理设备端的环境、代码和数据。
以下是描述GPU容量的两个重要特征。
- CUDA核心数量
- 内存大小
有两种不同的指标来评估GPU的性能。
- 峰值计算性能,峰值计算性能是用来评估计算容量的一个指标,通常定义为每秒能处理的单精度或双精度浮点运算的数量。峰值性能通常用
GFlops(每秒十亿次浮点运算)或TFlops(每秒万亿次浮点运算)来表示。 - 内存带宽,内存带宽是从内存中读取或写入数据的比率。内存带宽通常用
GB/s表示。
1.2.2 异构计算范例
GPU计算并不是要取代CPU计算。对于特定的程序来说,每种计算方法都有它自己的优点。CPU计算适合处理控制密集型任务,GPU计算适合处理包含数据并行的计算密集型任务。GPU与CPU结合后,能有效提高大规模计算问题的处理速度与性能。CPU针对动态工作负载进行了优化,这些动态工作负载是由短序列的计算操作和不可预测的控制流程标记的;而GPU在其他领域内的目的是:处理由计算任务主导的且带有简单控制流的工作负载。可以从两个方面来区分CPU和GPU应用的范围:
- 并行级
- 数据规模
如果一个问题有较小的数据规模、复杂的控制逻辑和/或很少的并行性,那么最好选择CPU处理该问题,因为它有处理复杂逻辑和指令级并行性的能力。相反,如果该问题包含较大规模的待处理数据并表现出大量的数据并行性,那么使用GPU是最好的选择。因为GPU中有大量可编程的核心,可以支持大规模多线程运算,而且相比CPU有较大的峰值带宽。
CPU上的线程通常是重量级的实体。操作系统必须交替线程使用启用或关闭CPU执行通道以提供多线程处理功能。上下文的切换缓慢且开销大。GPU上的线程是高度轻量级的。在一个典型的系统中会有成千上万的线程排队等待工作。如果GPU必须等待一组线程执行结束,那么它只要调用另一组线程执行其他任务即可。CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU的核是用来处理大量并发的、轻量级的线程,以最大限度地提高吞吐量。
1.2.3 CUDA:一种异构计算平台
CUDA是一种通用的并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎能更有效地解决复杂的计算问题。通过使用CUDA,你可以像在CPU上那样,通过GPU来进行计算。
CUDA提供了两层API来管理GPU设备和组织线程:
- CUDA驱动API,驱动API是一种低级API,它相对来说较难编程,但是它对于在GPU设备使用上提供了更多的控制。
- CUDA运行时API,运行时API是一个高级API,它在驱动API的上层实现。每个运行时API函数都被分解为更多传给驱动API的基本运算。
一个CUDA程序包含了以下两个部分的混合:
- 在CPU上运行的主机代码
- 在GPU上运行的设备代码
NVIDIA的CUDA nvcc编译器在编译过程中将设备代码从主机代码中分离出来,CUDA nvcc编译器是以广泛使用LLVM开源编译系统为基础的。主机代码是标准的C代码,使用C编译器进行编译。设备代码,也就是核函数,是用扩展的带有标记数据并行函数关键字的CUDA C语言编写的。设备代码通过nvcc进行编译。在链接阶段,在内核程序调用和显示GPU设备操作中添加CUDA运行时库。
1.3 用GPU输出Hello World
#include "../common/common.h"
#include <stdio.h>
/*
* A simple introduction to programming in CUDA. This program prints "Hello
* World from GPU! from 10 CUDA threads running on the GPU.
*/
__global__ void helloFromGPU()
{
printf("Hello World from GPU!\n");
}
int main(int argc, char **argv)
{
printf("Hello World from CPU!\n");
helloFromGPU<<<1, 10>>>();
CHECK(cudaDeviceReset());
return 0;
}nvcc hello.cu - o hello
./hello
Hello World from CPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!一个典型的CUDA编程结构包括5个主要步骤。
- 分配GPU内存。
- 从CPU内存中拷贝数据到GPU内存。
- 调用CUDA内核函数来完成程序指定的运算。
- 将数据从GPU拷回CPU内存。
- 释放GPU内存空间。
1.4 使用CUDA C编程
数据局部性在并行编程中是一个非常重要的概念。数据局部性指的是数据重用,以降低内存访问的延迟。数据局部性有两种基本类型。时间局部性是指在相对较短的时间段内数据和/或资源的重用。空间局部性是指在相对较接近的存储空间内数据元素的重用。现代的CPU架构使用大容量缓存来优化具有良好空间局部性和时间局部性的应用程序。设计高效利用CPU缓存的算法是程序员的工作。程序员必须处理低层的缓存优化,但由于线程在底层架构中的安排是透明的,所以这一点程序员是没有办法优化的。
CUDA中有内存层次和线程层次的概念,使用如下结构,有助于你对线程执行进行更高层次的控制和调度:
- 内存层次结构
- 线程层次结构
例如,在CUDA编程模型中使用的共享内存(一个特殊的内存)。共享内存可以视为一个被软件管理的高速缓存,通过为主内存节省带宽来大幅度提高运行速度。有了共享内存,你可以直接控制代码的数据局部性。
CUDA核中有3个关键抽象:线程组的层次结构,内存的层次结构以及障碍同步。这3个抽象是最小的一组语言扩展。
第2章 CUDA编程模型
2.1 CUDA编程模型概述
CUDA编程模型提供了一个计算机架构抽象作为应用程序和其可用硬件之间的桥梁。CUDA编程模型利用GPU架构的计算能力提供了以下几个特有功能:
- 一种通过层次结构在GPU中组织线程的方法
- 一种通过层次结构在GPU中访问内存的方法
2.1.1 CUDA编程结构
CUDA编程模型使用由C语言扩展生成的注释代码在异构计算系统中执行应用程序。在一个异构环境中包含多个CPU和GPU,每个GPU和CPU的内存都由一条PCI-Express总线分隔开。因此,需要注意区分以下内容:
- 主机:CPU及其内存(主机内存)
- 设备:GPU及其内存(设备内存)
CUDA 6.0之后,NVIDIA提出了名为统一寻址(Unified Memory)的编程模型的改进,它连接了主机内存和设备内存空间,可使用单个指针访问CPU和GPU内存,无须彼此之间手动拷贝数据。
内核(kernel)是CUDA编程模型的一个重要组成部分,其代码在GPU上运行。多数情况下,主机可以独立地对设备进行操作。内核一旦被启动,管理权立刻返回给主机,释放CPU来执行由设备上运行的并行代码实现的额外的任务。CUDA编程模型主要是异步的,因此在GPU上进行的运算可以与主机-设备通信重叠。一个典型的CUDA程序包括由并行代码互补的串行代码。
2.1.2 内存管理
用于执行GPU内存分配的是cudaMalloc函数,其函数原型为:
cudaError_t cudaMalloc(void** devPtr, size_t size)cudaMemcpy函数负责主机和设备之间的数据传输,其函数原型为:
cudaError_t cudaMemcmpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)这个函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cudaError_t。
CUDA编程模型最显著的一个特点就是揭示了内存层次结构。每一个GPU设备都有用于不同用途的存储类型。在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。然而GPU的共享内存可以由CUDA C的内核直接控制。
使用CUDA C进行编程的人最常犯的错误就是对不同内存空间的不恰当引用。对于在GPU上被分配的内存来说,设备指针在主机代码中可能并没有被引用。
2.1.3 线程管理
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程并且每个线程都执行由核函数指定的语句。了解如何组织线程是CUDA编程的一个关键部分。由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内的线程协作可以通过以下方式来实现。
- 同步
- 共享内存
不同块内的线程不能协作。线程依靠以下两个坐标变量来区分彼此:
- blockIdx(线程块在线程格内的索引)
- threadIdx(块内的线程索引)
CUDA可以组织三维的网格和块。网格和块的维度由下列两个内置变量指定。
- blockDim(线程块的维度,用每个线程块中的线程数来表示)
- gridDim(线程格的维度,用每个线程格中的线程数来表示)
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。线程格和线程块均使用3个dim3类型的无符号整型字段,而未使用的字段将被初始化为1且忽略不计。
checkDimension.cu定义了一个包含3个线程的一维线程块,以及一个基于块和数据大小定义的一定数量线程块的一维线程网格:
grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
threadIdx:(0, 0, 0)
threadIdx:(1, 0, 0)
threadIdx:(2, 0, 0)
threadIdx:(0, 0, 0)
threadIdx:(1, 0, 0)
threadIdx:(2, 0, 0)
blockIdx:(0, 0, 0)
blockIdx:(0, 0, 0)
blockIdx:(0, 0, 0)
blockIdx:(1, 0, 0)
blockIdx:(1, 0, 0)
blockIdx:(1, 0, 0)
blockDim:(3, 1, 1)
blockDim:(3, 1, 1)
blockDim:(3, 1, 1)
blockDim:(3, 1, 1)
blockDim:(3, 1, 1)
blockDim:(3, 1, 1)
gridDim:(2, 1, 1)
gridDim:(2, 1, 1)
gridDim:(2, 1, 1)
gridDim:(2, 1, 1)
gridDim:(2, 1, 1)
gridDim:(2, 1, 1)对于一个给定的数据大小,确定网格和块尺寸的一般步骤为:
- 确定块的大小
- 在已知数据大小和块大小的基础上计算网格维度
要确定块尺寸,通常需要考虑:
- 内核的性能特性
- GPU资源的限制
defineGridBlock.cu使用了一个一维网格和一个一维块来说明当块的大小改变时,网格的尺寸也会随之改变。由于应用程序中的数据大小是固定的,因此当块的大小发生改变时,相应的网格尺寸也会发生改变。
grid.x 1 block.x 1024
grid.x 2 block.x 512
grid.x 4 block.x 256
grid.x 8 block.x 128CUDA的特点之一就是通过编程模型揭示了一个两层的线程层次结构。由于一个内核启动的网格和块的维数会影响性能,这一结构为程序员优化程序提供了一个额外的途径。网格和块的维度存在几个限制因素,对于块大小的一个主要限制因素就是可利用的计算资源,如寄存器,共享内存等。
2.1.4 启动一个CUDA核函数
CUDA内核调用是对C语言函数调用语句的延伸,<<<>>>运算符内是核函数的执行配置。
kernel_name <<<grid, block>>>(args list)通过指定网格和块的维度,你可以进行以下配置:
- 内核中线程的数目
- 内核中使用的线程布局
核函数的调用与主机线程是异步的。核函数调用结束后,控制权立刻返回给主机端。你可以调用以下函数来强制主机端程序等待所有的核函数执行结束:
cudaError_t cudaDeviceSynchronize(void);一些CUDA运行时API在主机和设备之间是隐式同步的。当使用cudaMemcpy函数在主机和设备之间拷贝数据时,主机端隐式同步,即主机端程序必须等待数据拷贝完成后才能继续执行程序。
2.1.5 编写核函数
核函数是在设备端执行的代码。在核函数中,需要为一个线程规定要进行的计算以及要进行的数据访问。当核函数被调用时,许多不同的CUDA线程并行执行同一个计算任务。核函数必须有一个void返回类型。以下是用__global__声明定义核函数:
__global__ void kernel_name(args list);__global__:在设备端执行,可以从主机端或计算能力3.0的设备中调用__device__:在设备端执行,仅能从设备端调用__host__:在主机端执行,仅能从主机端调用,可以省略
__device__和__host__限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译。以下限制适用于所有核函数:
- 只能访问设备内存
- 必须具有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
2.1.6 验证核函数
略
2.1.7 处理错误
略
2.1.8 编译和执行
./sumArraysOnGPU-small-case Starting...
Vector size 32
Execution configure <<<1, 32>>>
Arrays match.2.2 给核函数计时
衡量核函数性能的方法有很多。最简单的方法是在主机端使用一个CPU或GPU计时器来计算内核的执行时间。
2.2.1 用CPU计时器计时
sumArraysOnGPU-timer.cu展示了如何在主函数中用CPU计时器测试向量加法的核函数。
./sumArraysOnGPU-timer Starting...
Using Device 0: Orin
Vector size 16777216
initialData Time elapsed 1.048767 sec
sumArraysOnHost Time elapsed 0.075818 sec
sumArraysOnGPU <<< 32768, 512 >>> Time elapsed 0.004480 sec
Arrays match.
# sumArraysOnGPU <<< 131072, 128 >>> Time elapsed 0.004350 sec
# sumArraysOnGPU <<< 65536, 256 >>> Time elapsed 0.004323 sec
# sumArraysOnGPU <<< 16384, 1024 >>> Time elapsed 0.006946 sec2.2.2 用nvprof工具计时
Tegra不支持。略
2.3 组织并行线程
现在通过一个矩阵加法的例子来进一步说明这一点。对于矩阵运算,传统的方法是在内核中使用一个包含二维网格与二维块的布局来组织线程。但是,这种传统的方法无法获得最佳性能。在矩阵加法中使用以下布局将有助于了解更多关于网格和块的启发性的用法:
- 由二维线程块构成的二维网格
- 由一维线程块构成的一维网格
- 由一维线程块构成的二维网格
2.3.1 使用块和线程建立矩阵索引
checkThreadIndex.cu检查块和线程索引:线程索引,块索引,矩阵坐标,线性全局内存偏移量,相应元素的值
./checkThreadIndex Starting...
Using Device 0: Orin
Matrix: (8.6)
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31
32 33 34 35 36 37 38 39
40 41 42 43 44 45 46 47
thread_id (0,0) block_id (1,1) coordinate (4,2) global index 20 ival 20
thread_id (1,0) block_id (1,1) coordinate (5,2) global index 21 ival 21
thread_id (2,0) block_id (1,1) coordinate (6,2) global index 22 ival 22
thread_id (3,0) block_id (1,1) coordinate (7,2) global index 23 ival 23
thread_id (0,1) block_id (1,1) coordinate (4,3) global index 28 ival 28
thread_id (1,1) block_id (1,1) coordinate (5,3) global index 29 ival 29
thread_id (2,1) block_id (1,1) coordinate (6,3) global index 30 ival 30
thread_id (3,1) block_id (1,1) coordinate (7,3) global index 31 ival 31
thread_id (0,0) block_id (1,0) coordinate (4,0) global index 4 ival 4
thread_id (1,0) block_id (1,0) coordinate (5,0) global index 5 ival 5
thread_id (2,0) block_id (1,0) coordinate (6,0) global index 6 ival 6
thread_id (3,0) block_id (1,0) coordinate (7,0) global index 7 ival 7
thread_id (0,1) block_id (1,0) coordinate (4,1) global index 12 ival 12
thread_id (1,1) block_id (1,0) coordinate (5,1) global index 13 ival 13
thread_id (2,1) block_id (1,0) coordinate (6,1) global index 14 ival 14
thread_id (3,1) block_id (1,0) coordinate (7,1) global index 15 ival 15
thread_id (0,0) block_id (0,1) coordinate (0,2) global index 16 ival 16
thread_id (1,0) block_id (0,1) coordinate (1,2) global index 17 ival 17
thread_id (2,0) block_id (0,1) coordinate (2,2) global index 18 ival 18
thread_id (3,0) block_id (0,1) coordinate (3,2) global index 19 ival 19
thread_id (0,1) block_id (0,1) coordinate (0,3) global index 24 ival 24
thread_id (1,1) block_id (0,1) coordinate (1,3) global index 25 ival 25
thread_id (2,1) block_id (0,1) coordinate (2,3) global index 26 ival 26
thread_id (3,1) block_id (0,1) coordinate (3,3) global index 27 ival 27
thread_id (0,0) block_id (1,2) coordinate (4,4) global index 36 ival 36
thread_id (1,0) block_id (1,2) coordinate (5,4) global index 37 ival 37
thread_id (2,0) block_id (1,2) coordinate (6,4) global index 38 ival 38
thread_id (3,0) block_id (1,2) coordinate (7,4) global index 39 ival 39
thread_id (0,1) block_id (1,2) coordinate (4,5) global index 44 ival 44
thread_id (1,1) block_id (1,2) coordinate (5,5) global index 45 ival 45
thread_id (2,1) block_id (1,2) coordinate (6,5) global index 46 ival 46
thread_id (3,1) block_id (1,2) coordinate (7,5) global index 47 ival 47
thread_id (0,0) block_id (0,0) coordinate (0,0) global index 0 ival 0
thread_id (1,0) block_id (0,0) coordinate (1,0) global index 1 ival 1
thread_id (2,0) block_id (0,0) coordinate (2,0) global index 2 ival 2
thread_id (3,0) block_id (0,0) coordinate (3,0) global index 3 ival 3
thread_id (0,1) block_id (0,0) coordinate (0,1) global index 8 ival 8
thread_id (1,1) block_id (0,0) coordinate (1,1) global index 9 ival 9
thread_id (2,1) block_id (0,0) coordinate (2,1) global index 10 ival 10
thread_id (3,1) block_id (0,0) coordinate (3,1) global index 11 ival 11
thread_id (0,0) block_id (0,2) coordinate (0,4) global index 32 ival 32
thread_id (1,0) block_id (0,2) coordinate (1,4) global index 33 ival 33
thread_id (2,0) block_id (0,2) coordinate (2,4) global index 34 ival 34
thread_id (3,0) block_id (0,2) coordinate (3,4) global index 35 ival 35
thread_id (0,1) block_id (0,2) coordinate (0,5) global index 40 ival 40
thread_id (1,1) block_id (0,2) coordinate (1,5) global index 41 ival 41
thread_id (2,1) block_id (0,2) coordinate (2,5) global index 42 ival 42
thread_id (3,1) block_id (0,2) coordinate (3,5) global index 43 ival 432.3.2 使用二维网格和二维块对矩阵求和
sumMatrixOnGPU-2D-grid-2D-block.cu
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
// ...
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);2.3.3 使用一维网格和一维块对矩阵求和
sumMatrixOnGPU-1D-grid-1D-block.cu
// grid 1D block 1D
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx )
for (int iy = 0; iy < ny; iy++)
{
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
// ...
// invoke kernel at host side
int dimx = 32;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, 1);2.3.4 使用二维网格和一维块对矩阵求和
sumMatrixOnGPU-2D-grid-1D-block.cu
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx,
int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
// ...
// invoke kernel at host side
int dimx = 32;
dim3 block(dimx, 1);
dim3 grid((nx + block.x - 1) / block.x, ny);从矩阵加法的例子中可以看出:
- 改变执行配置对内核性能有影响
- 传统的核函数实现一般不能获得最佳性能
- 对于一个给定的核函数,尝试使用不同的网格和线程块大小可以获得更好的性能
2.4 设备管理
2.4.1 使用运行时API查询GPU信息
可以使用以下函数查询关于GPU设备的所有信息:
cudaError_t cudaGetDeviceProperties(cudaDeviceProp* prop, int device)checkDeviceInfor.cu将返回所安装设备的不同信息。
./checkDeviceInfor Starting...
Detected 1 CUDA Capable device(s)
Device 0: "Orin"
CUDA Driver Version / Runtime Version 11.4 / 11.4
CUDA Capability Major/Minor version number: 8.7
Total amount of global memory: 7.16 GBytes (7693115392 bytes)
GPU Clock rate: 624 MHz (0.62 GHz)
Memory Clock rate: 624 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 2097152 bytes
Max Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384)
Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes2.4.2 确定最优GPU
一些系统支持多GPU。在每个GPU都不同的情况下,选择性能最好的GPU运行核函数是非常重要的。通过比较GPU包含的多处理器的数量选出计算能力最佳的GPU。
2.4.3 使用nvidia-smi查询GPU信息
Jetson不支持nvidia-smi,略。补充:可以通过Jtop查看。
2.4.4 在运行时设置设备
设置运行时环境变量CUDA_VISIBLE_DEVICES=2。nvidia驱动程序会屏蔽其他GPU,这时设备2作为设备0出现在应用程序中。也可以使用CUDA_VISIBLE_DEVICES指定多个设备。例如,如果想测试GPU 2和GPU 3,可以设置CUDA_VISIBLE_DEVICES=2,3。然后,在运行时,nvidia驱动程序将只使用ID为2和3的设备,并且会将设备ID分别映射为0和1。
第3章 CUDA执行模型
3.1 CUDA执行模型概述
GPU架构是围绕一个流式多处理器(SM)的可扩展阵列搭建的。可以通过复制这种架构的构建块来实现GPU的硬件并行。Fermi SM的关键组件:
- CUDA核心
- 共享内存/一级缓存
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器
GPU中的每一个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,所以在一个GPU上并发执行数千个线程是有可能的。当启动一个内核网格时,它的线程块被分布在了可用的SM上来执行。线程块一旦被调度到一个SM上,其中的线程只会在那个指定的SM上并发执行。多个线程块可能会被分配到同一个SM上,而且是根据SM资源的可用性进行调度的。同一线程中的指令利用指令级并行性进行流水线化。
CUDA采用单指令多线程(SIMT)架构来管理和执行线程,每32个线程为一组,被称为线程束(warp)。线程束中的所有线程同时执行相同的指令。每个线程都有自己的指令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个SM都将分配给它的线程块划分到包含32个线程的线程束中,然后在可用的硬件资源上调度执行。
SIMT架构与SIMD(单指令多数据)架构相似。两者都是将相同的指令广播给多个执行单元来实现并行。一个关键的区别是SIMD要求同一个向量中的所有元素要在一个统一的同步组中一起执行,而SIMT允许属于同一线程束的多个线程独立执行。尽管一个线程束中的所有线程在相同的程序地址上同时开始执行,但是单独的线程仍有可能有不同的行为。SIMT确保可以编写独立的线程级并行代码、标量线程以及用于协调线程的数据并行代码。SIMT模型包含3个SIMD所不具备的关键特征。
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
一个神奇的数字:32。32在CUDA程序里是一个神奇的数字。它来自于硬件系统,也对软件的性能有着重要的影响。从概念上讲,它是SM用SIMD方式所同时处理的工作粒度。优化工作负载以适应线程束(一组有32个线程)的边界,一般这样会更有效地利用GPU计算资源。
SM:GPU架构的核心。SM是GPU架构的核心。寄存器和共享内存是SM中的稀缺资源。CUDA将这些资源分配到SM中的所有常驻线程里。因此,这些有限的资源限制了在SM上活跃的线程束数量,活跃的线程束数量对应于SM上的并行量。
一个线程块只能在一个SM上被调度。一旦线程块在一个SM上被调度,就会保存在该SM上直到执行完成。在同一时间,一个SM可以容纳多个线程块。在SM中,共享内存和寄存器是非常重要的资源。共享内存被分配在SM上的常驻线程块中,寄存器在线程中被分配。线程块中的线程通过这些资源可以进行相互的合作和通信。尽管线程块里的所有线程都可以逻辑地并行运行,但是并不是所有线程都可以同时在物理层面执行。因此,线程块里的不同线程可能会以不同的速度前进。
并发竞争:在并行线程中共享数据可能会引起竞争:多个线程使用未定义的顺序访问同一个数据,从而导致不可预测的程序行为。CUDA提供了一种用来同步线程块里的线程的方法,从而保证所有线程在进一步动作之前都达到执行过程中的一个特定点。然而,没有提供块间同步的原语。
调度:尽管线程块里的线程束可以任意顺序调度,但活跃的线程束的数量还是会由SM的资源所限制。当线程束由于任何理由闲置的时候(如等待从设备内存中读取数值),SM可以从同一SM上的常驻线程块中调度其他可用的线程束。在并发的线程束间切换并没有开销,因为硬件资源已经被分配到了SM上的所有线程和块中,所以最新被调度的线程束的状态已经存储在SM上。
3.1.1 GPU架构概述
3.1.2 Fermi架构
一个SM,包含了以下内容:
- 执行单元(CUDA核心)
- 调度线程束的调度器和调度单元
- 共享内存、寄存器文件和一级缓存
每一个多处理器有16个加载/存储单元(如图3-1所示),允许每个时钟周期内有16个线程(线程束的一半)计算源地址和目的地址。特殊功能单元(SFU)执行固有指令,如正弦、余弦、平方根和插值。每个SFU在每个时钟周期内的每个线程上执行一个固有指令。
3.1.3 Kepler架构
Kepler架构的3个重要的创新。
- 强化的SM
- 动态并行
- Hyper-Q技术
动态并行是Kepler GPU的一个新特性,它允许GPU动态启动新的网格。有了这个特点,任一内核都能启动其他的内核,并且管理任何核间需要的依赖关系来正确地执行附加的工作。这一特点也让你更容易创建和优化递归及与数据相关的执行模式。有了动态并行,GPU能够启动嵌套内核,消除了与CPU通信的需求。动态并行拓宽了GPU在各种学科上的适用性。动态地启动小型和中型的并行工作负载,这在以前是需要很高代价的。
Hyper-Q技术增加了更多的CPU和GPU之间的同步硬件连接,以确保CPU核心能够在GPU上同时运行更多的任务。因此,当使用Kepler GPU时,既可以增加GPU的利用率,也可以减少CPU的闲置时间。
3.1.4 配置文件驱动优化
性能分析是通过检测来分析程序性能的行为:
- 应用程序代码的空间(内存)或时间复杂度
- 特殊指令的使用
- 函数调用的频率和持续时间
开发一个HPC应用程序通常包括两个主要步骤:
- 提高代码的正确性
- 提高代码的性能
配置文件驱动的发展对于CUDA编程尤为重要,原因主要有以下几个方面。
- 一个单纯的内核应用一般不会产生最佳的性能。性能分析工具能帮助你找到代码中影响性能的关键部分,也就是性能瓶颈。
- CUDA将SM中的计算资源在该SM中的多个常驻线程块之间进行分配。这种分配形式导致一些资源成为了性能限制者。性能分析工具能帮助我们理解计算资源是如何被利用的。
- CUDA提供了一个硬件架构的抽象,它能够让用户控制线程并发。性能分析工具可以检测和优化,并将优化可视化。
在CUDA性能分析中,事件是可计算的活动,它对应一个在内核执行期间被收集的硬件计数器。指标是内核的特征,它由一个或多个事件计算得到。请记住以下概念事件和指标:
- 大多数计数器通过流式多处理器来报告,而不是通过整个GPU。
- 一个单一的运行只能获得几个计数器。有些计数器的获得是相互排斥的。多个性能分析运行往往需要获取所有相关的计数器。
- 由于GPU执行中的变化(如线程块和线程束调度指令),经重复运行,计数器值可能不是完全相同的。
有3种常见的限制内核性能的因素:
- 存储带宽
- 计算资源
- 指令和内存延迟
3.2 理解线程束执行的本质
3.2.1 线程束和线程块
线程束是SM中基本的执行单元。当一个线程块的网格被启动后,网格中的线程块分布在SM中。一旦线程块被调度到一个SM上,线程块中的线程会被进一步划分为线程束。一个线程束由32个连续的线程组成,在一个线程束中,所有的线程按照单指令多线程(SIMT)方式执行;也就是说,所有线程都执行相同的指令,每个线程在私有数据上进行操作。例如,一个有128个线程的一维线程块被组织到4个线程束里。
对于一个给定的二维线程块,在一个块中每个线程的独特标识符都可以用内置变量threadIdx和blockDim来计算:
threadIdx.y * blockDim.x + threadIdx.x对于一个三维线程块,计算如下:
threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x一个线程块的线程束的数量可以根据下式确定:
$$
N=向正无穷取整(\frac{线程块中线程数量}{WarpSize})
$$
硬件总是给一个线程块分配一定数量的线程束。线程束不会在不同的线程块之间分离。如果线程块的大小不是线程束大小的偶数倍,那么在最后的线程束里有些线程就不会活跃。
从逻辑角度来看,线程块是线程的集合,它们可以被组织为一维、二维或三维布局。从硬件角度来看,线程块是一维线程束的集合。在线程块中线程被组织成一维布局,每32个连续线程组成一个线程束。
3.2.2 线程束分化
GPU是相对简单的设备,它没有复杂的分支预测机制。一个线程束中的所有线程在同一周期中必须执行相同的指令,如果一个线程执行一条指令,那么线程束中的所有线程都必须执行该指令。如果在同一线程束中的线程使用不同的路径通过同一个应用程序,这可能会产生问题。
if (cond) {
...
} else {
...
}假设在一个线程束中有16个线程执行这段代码,cond为true,但对于其他16个来说cond为false。一半的线程束需要执行if语句块中的指令,而另一半需要执行else语句块中的指令。在同一线程束中的线程执行不同的指令,被称为线程束分化。如果一个线程束中的线程产生分化,线程束将连续执行每一个分支路径,而禁用不执行这一路径的线程。线程束分化会导致性能明显地下降。在前面的例子中可以看到,线程束中并行线程的数量减少了一半:只有16个线程同时活跃地执行,而其他16个被禁用了。条件分支越多,并行性削弱越严重。注意,线程束分化只发生在同一个线程束中。在不同的线程束中,不同的条件值不会引起线程束分化。
为了获得最佳的性能,应该避免在同一线程束中有不同的执行路径。请记住,在一个线程块中,线程的线程束分配是确定的。因此,以这样的方式对数据进行分区是可行的(尽管不是微不足道的,但取决于算法),以确保同一个线程束中的所有线程在一个应用程序中使用同一个控制路径。例如,假设有两个分支,下面展示了简单的算术内核示例mathKernel1。我们可以用一个偶数和奇数线程方法来模拟一个简单的数据分区,目的是导致线程束分化。该条件(tid%2==0)使偶数编号的线程执行if子句,奇数编号的线程执行else子句。如果使用线程束方法(而不是线程方法)来交叉存取数据,可以避免线程束分化,并且设备的利用率可达到100%。mathKernel2条件(tid/warpSize)%2==0使分支粒度是线程束大小的倍数;偶数编号的线程执行if子句,奇数编号的线程执行else子句。这个核函数产生相同的输出,但是顺序不同。
simpleDivergence.cu简单的线程束分化。注:代码中iStart等需改为double。
因为在设备上第一次运行可能会增加间接开销,并且在此处测量的性能是非常精细的,所以,添加了一个额外的内核启动(warmingup,与mathKernel2一样)来去除这一间接开销。
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if (tid % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if ((tid / warpSize) % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel3(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
bool ipred = (tid % 2 == 0);
if (ipred)
{
ia = 100.0f;
}
if (!ipred)
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void mathKernel4(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
int itid = tid >> 5;
if (itid & 0x01 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}
__global__ void warmingup(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
if ((tid / warpSize) % 2 == 0)
{
ia = 100.0f;
}
else
{
ib = 200.0f;
}
c[tid] = ia + ib;
}./simpleDivergence 32 64
./simpleDivergence using Device 0: Orin
Data size 64 Execution Configure (block 32 grid 2)
warmup <<< 2 32 >>> elapsed 0.000557 sec
mathKernel1 <<< 2 32 >>> elapsed 0.000036 sec
mathKernel2 <<< 2 32 >>> elapsed 0.000037 sec
mathKernel3 <<< 2 32 >>> elapsed 0.000029 sec
mathKernel4 <<< 2 32 >>> elapsed 0.000026 sec分支效率被定义为未分化的分支与全部分支之比,可以使用以下公式来计算:
$$
分支效率 = \frac{分支数 - 分支分化数}{分支数} * 100
$$
奇怪的是,没有报告显示出有分支分化(即分支效率是100%)。这个奇怪的现象是CUDA编译器优化导致的结果,它将短的、有条件的代码段的断定指令取代了分支指令(导致分化的实际控制流指令)。在分支预测中,根据条件,把每个线程中的一个断定变量设置为1或0。这两种条件流路径被完全执行,但只有断定为1的指令被执行。断定为0的指令不被执行,但相应的线程也不会停止。这和实际的分支指令之间的区别是微妙的,但理解它很重要。只有在条件语句的指令数小于某个阈值时,编译器才用断定指令替换分支指令。因此,一段很长的代码路径肯定会导致线程束分化。
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float ia, ib;
ia = ib = 0.0f;
bool ipred = (tid % 2 == 0);
if (ipred)
{
ia = 100.0f;
}
if (!ipred)
{
ib = 200.0f;
}
c[tid] = ia + ib;
}nvcc -g -G simpleDivergence.cu -o simpleDivergence # 可以强制CUDA编译器不利用分支预测去优化内核
./simpleDivergence 32 64
./simpleDivergence using Device 0: Orin
Data size 64 Execution Configure (block 32 grid 2)
warmup <<< 2 32 >>> elapsed 0.000550 sec
mathKernel1 <<< 2 32 >>> elapsed 0.000054 sec
mathKernel2 <<< 2 32 >>> elapsed 0.000039 sec
mathKernel3 <<< 2 32 >>> elapsed 0.000033 sec
mathKernel4 <<< 2 32 >>> elapsed 0.000028 sec- 当一个分化的线程采取不同的代码路径时,会产生线程束分化
- 不同的if-then-else分支会连续执行
- 尝试调整分支粒度以适应线程束大小的倍数,避免线程束分化
- 不同的分化可以执行不同的代码且无须以牺牲性能为代价
3.2.3 资源分配
线程束的本地执行上下文主要由以下资源组成:
- 程序计数器
- 寄存器
- 共享内存
由SM处理的每个线程束的执行上下文,在整个线程束的生存期中是保存在芯片内的。因此,从一个执行上下文切换到另一个执行上下文没有损失。每个SM都有32位的寄存器组,它存储在寄存器文件中,并且可以在线程中进行分配,同时固定数量的共享内存用来在线程块中进行分配。对于一个给定的内核,同时存在于同一个SM中的线程块和线程束的数量取决于在SM中可用的且内核所需的寄存器和共享内存的数量。
- 若每个线程消耗的寄存器越多,则可以放在一个SM中的线程束就越少。如果可以减少内核消耗寄存器的数量,那么就可以同时处理更多的线程束。
- 若一个线程块消耗的共享内存越多,则在一个SM中可以被同时处理的线程块就会变少。如果每个线程块使用的共享内存数量变少,那么可以同时处理更多的线程块。
当计算资源(如寄存器和共享内存)已分配给线程块时,线程块被称为活跃的块。它所包含的线程束被称为活跃的线程束。活跃的线程束可以进一步被分为以下3种类型:
- 选定的线程束
- 阻塞的线程束
- 符合条件的线程束
一个SM上的线程束调度器在每个周期都选择活跃的线程束,然后把它们调度到执行单元。活跃执行的线程束被称为选定的线程束。如果一个活跃的线程束准备执行但尚未执行,它是一个符合条件的线程束。如果一个线程束没有做好执行的准备,它是一个阻塞的线程束。如果同时满足以下两个条件则线程束符合执行条件。
- 32个CUDA核心可用于执行
- 当前指令中所有的参数都已就绪
3.2.4 延迟隐藏
SM依赖线程级并行,以最大化功能单元的利用率,因此,利用率与常驻线程束的数量直接相关。在指令发出和完成之间的时钟周期被定义为指令延迟。当每个时钟周期中所有的线程调度器都有一个符合条件的线程束时,可以达到计算资源的完全利用。这就可以保证,通过在其他常驻线程束中发布其他指令,可以隐藏每个指令的延迟。与在CPU上用C语言编程相比,延迟隐藏在CUDA编程中尤为重要。CPU核心是为同时最小化延迟一个或两个线程而设计的,而GPU则是为处理大量并发和轻量级线程以最大化吞吐量而设计的。GPU的指令延迟被其他线程束的计算隐藏。考虑到指令延迟,指令可以被分为两种基本类型:
- 算术指令,算术指令延迟是一个算术操作从开始到它产生输出之间的时间。算术操作为10~20个周期
- 内存指令,内存指令延迟是指发送出的加载或存储操作和数据到达目的地之间的时间。全局内存访问为400~800个周期
如何估算隐藏延迟所需要的活跃线程束的数量。利特尔法则(Little’s Law)可以提供一个合理的近似值。它起源于队列理论中的一个定理,它也可以应用于GPU中:$$所需线程束数量 = 延迟 * 吞吐量$$
假设在内核里一条指令的平均延迟是5个周期。为了保持在每个周期内执行6个线程束的吞吐量,则至少需要30个未完成的线程束。
带宽和吞吐量经常被混淆,根据实际情况它们可以被交换使用。吞吐量和带宽都是用来度量性能的速度指标。带宽通常是指理论峰值,而吞吐量是指已达到的值。带宽通常是用来描述单位时间内最大可能的数据传输量,而吞吐量是用来描述单位时间内任何形式的信息或操作的执行速度,例如,每个周期完成多少个指令。对于算术运算来说,其所需的并行可以表示成隐藏算术延迟所需要的操作数量。算术运算是一个32位的浮点数乘加运算(a+b×c),表示在每个SM中每个时钟周期内的操作数量。吞吐量因不同的算术指令而不同。算术运算所需的并行可以用操作的数量或线程束的数量来表示。这个简单的单位转换表明,
有两种方法可以提高并行:
- 指令级并行(ILP):一个线程中有很多独立的指令
- 线程级并行(TLP):很多并发地符合条件的线程
与指令延迟很像,通过在每个线程/线程束中创建更多独立的内存操作,或创建更多并发地活跃的线程/线程束,可以增加可用的并行。延迟隐藏取决于每个SM中活跃线程束的数量,这一数量由执行配置和资源约束隐式决定(一个内核中寄存器和共享内存的使用情况)。选择一个最优执行配置的关键是在延迟隐藏和资源利用之间找到一种平衡。
因为GPU在线程间分配计算资源并在并发线程束之间切换的消耗(在一个或两个周期命令上)很小,所以所需的状态可以在芯片内获得。如果有足够的并发活跃线程,那么可以让GPU在每个周期内的每一个流水线阶段中忙碌。在这种情况下,一个线程束的延迟可以被其他线程束的执行隐藏。因此,向SM显示足够的并行对性能是有利的。计算所需并行的一个简单的公式是,用每个SM核心的数量乘以在该SM上一条算术指令的延迟。例如,Fermi有32个单精度浮点流水线线路,一个算术指令的延迟是20个周期,所以,每个SM至少需要有32×20=640个线程使设备处于忙碌状态。然而,这只是一个下边界。
3.2.5 占用率
在每个CUDA核心里指令是顺序执行的。当一个线程束阻塞时,SM切换执行其他符合条件的线程束。理想情况下,我们想要有足够的线程束占用设备的核心。占用率是每个SM中活跃的线程束占最大线程束数量的比值。
$$
占用率 = \frac{活跃线程束数量}{最大线程束数量} * 100
$$
simpleDeviceQuery.cu展示了如何使用cudaGetDeviceProperties获得GPU的配置信息。
Device 0: Orin
Number of multiprocessors: 8
Total amount of constant memory: 64.00 KB
Total amount of shared memory per block: 48.00 KB
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum number of threads per multiprocessor: 1536
Maximum number of warps per multiprocessor: 48在确定GPU的计算能力后,物理限制部分的数据是自动填充的。接下来,需要输入以下内核资源信息:
- 每个块的线程(执行配置)
- 每个线程的寄存器(资源使用情况)
- 每个块的共享内存(资源使用情况)
每个线程的寄存器和每个块的共享内存资源的使用情况可以从nvcc中用以下编译器标志获得:
--ptxas-options=-v
nvcc simpleDivergence.cu -o simpleDivergence --ptxas-options=-v
ptxas info : 0 bytes gmem
ptxas info : Compiling entry function '_Z9warmingupPf' for 'sm_52'
ptxas info : Function properties for _Z9warmingupPf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 10 registers, 328 bytes cmem[0], 4 bytes cmem[2]
ptxas info : Compiling entry function '_Z11mathKernel4Pf' for 'sm_52'
ptxas info : Function properties for _Z11mathKernel4Pf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 4 registers, 328 bytes cmem[0]
ptxas info : Compiling entry function '_Z11mathKernel3Pf' for 'sm_52'
ptxas info : Function properties for _Z11mathKernel3Pf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 4 registers, 328 bytes cmem[0], 4 bytes cmem[2]
ptxas info : Compiling entry function '_Z11mathKernel2Pf' for 'sm_52'
ptxas info : Function properties for _Z11mathKernel2Pf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 10 registers, 328 bytes cmem[0], 4 bytes cmem[2]
ptxas info : Compiling entry function '_Z11mathKernel1Pf' for 'sm_52'
ptxas info : Function properties for _Z11mathKernel1Pf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 4 registers, 328 bytes cmem[0], 4 bytes cmem[2]内核使用的寄存器数量会对常驻线程束数量产生显著的影响。寄存器的使用可以用下面的nvcc标志手动控制:
-maxrregcount=NUM-maxrregcount选项告诉编译器每个线程使用的寄存器数量不能超过NUM个。使用这个编译器标志,可以得到占用率计算器推荐的寄存器数量,同时使用这个数值可以改善应用程序的性能。
为了提高占用率,还需要调整线程块配置或重新调整资源的使用情况,以允许更多的线程束同时处于活跃状态和提高计算资源的利用率。极端地操纵线程块会限制资源的利用
- 小线程块:每个块中线程太少,会在所有资源被充分利用之前导致硬件达到每个SM的线程束数量的限制。
- 大线程块:每个块中有太多的线程,会导致在每个SM中每个线程可用的硬件资源较少。
网格和线程块大小的准则:
- 保持每个块中线程数量是线程束大小(32)的倍数
- 避免块太小:每个块至少要有128或256个线程
- 根据内核资源的需求调整块大小块的数量要远远多于SM的数量,从而在设备中可以显示有足够的并行
- 通过实验得到最佳执行配置和资源使用情况
尽管在每种情况下会遇到不同的硬件限制,但它们都会导致计算资源未被充分利用,阻碍隐藏指令和内存延迟的并行的建立。占用率唯一注重的是在每个SM中并发线程或线程束的数量。然而,充分的占用率不是性能优化的唯一目标。内核一旦达到一定级别的占用率,进一步增加占用率可能不会改进性能。
3.2.6 同步
栅栏同步是一个原语,它在许多并行编程语言中都很常见。在CUDA中,同步可以在两个级别执行:
- 系统级:等待主机和设备完成所有的工作
- 块级:在设备执行过程中等待一个线程块中所有线程到达同一点
对于主机来说,由于许多CUDA API调用和所有的内核启动不是同步的,cudaDeviceSynchronize函数可以用来阻塞主机应用程序,直到所有的CUDA操作(复制、 核函数等)完成。因为在一个线程块中线程束以一个未定义的顺序被执行,CUDA提供了一个使用块局部栅栏来同步它们的执行的功能。使用下述函数在内核中标记同步点:
__device__ void __syncthreads(void);当__syncthreads被调用时,在同一个线程块中每个线程都必须等待直至该线程块中所有其他线程都已经达到这个同步点。在栅栏之前所有线程产生的所有全局内存和共享内存访问,将会在栅栏后对线程块中所有其他的线程可见。该函数可以协调同一个块中线程之间的通信,但它强制线程束空闲,从而可能对性能产生负面影响。
线程块中的线程可以通过共享内存和寄存器来共享数据。当线程之间共享数据时,要避免竞争条件。竞争条件或危险,是指多个线程无序地访问相同的内存位置。例如,当一个位置的无序读发生在写操作之后时,写后读竞争条件发生。因为读和写之间没有顺序,所以读应该在写前还是在写后加载值是未定义的。其他竞争条件的例子有读后写或写后写。当线程块中的线程在逻辑上并行运行时,在物理上并不是所有的线程都可以在同一时间执行。如果线程A试图读取由线程B在不同的线程束中写的数据,若使用了适当的同步,只需确定线程B已经写完就可以了。否则,会出现竞争条件。
在不同的块之间没有线程同步。块间同步,唯一安全的方法是在每个内核执行结束端使用全局同步点;也就是说,在全局同步之后,终止当前的核函数,开始执行新的核函数。不同块中的线程不允许相互同步,因此GPU可以以任意顺序执行块。这使得CUDA程序在大规模并行GPU上是可扩展的。
3.2.7 可扩展性
对于任何并行应用程序而言,可扩展性是一个理想的特性。可扩展性意味着为并行应用程序提供了额外的硬件资源,相对于增加的资源,并行应用程序会产生加速。例如,若一个CUDA程序在两个SM中是可扩展的,则与在一个SM中运行相比,在两个SM中运行会使运行时间减半。一个可扩展的并行程序可以高效地使用所有的计算资源以提高性能。可扩展性意味着增加的计算核心可以提高性能。串行代码本身是不可扩展的,因为在成千上万的内核上运行一个串行单线程应用程序,对性能是没有影响的。并行代码有可扩展的潜能,但真正的可扩展性取决于算法设计和硬件特性。
能够在可变数量的计算核心上执行相同的应用程序代码的能力被称为透明可扩展性。一个透明的可扩展平台拓宽了现有应用程序的应用范围,并减少了开发人员的负担,因为它们可以避免新的或不同的硬件产生的变化。可扩展性比效率更重要。一个可扩展但效率很低的系统可以通过简单添加硬件核心来处理更大的工作负载。一个效率很高但不可扩展的系统可能很快会达到可实现性能的上限。
CUDA内核启动时,线程块分布在多个SM中。网格中的线程块以并行或连续或任意的顺序被执行。这种独立性使得CUDA程序在任意数量的计算核心间可以扩展。若GPU有两个SM,可以同时执行两个块;假使GPU有4个SM,则可以同时执行4个块。不修改任何代码,一个应用程序可以在不同的GPU配置上运行,并且所需的执行时间根据可用的资源而改变。
3.3 并行性的表现
sumMatrix.cu对块和网格配置执行试验。
3.3.1 用nvprof检测活跃的线程束
➜ chapter03 ./sumMatrix 32 32
sumMatrixOnGPU2D <<<(128,128), (32,32)>>> elapsed 0.005473 ms
➜ chapter03 ./sumMatrix 32 16
sumMatrixOnGPU2D <<<(128,256), (32,16)>>> elapsed 0.003788 ms
➜ chapter03 ./sumMatrix 16 32
sumMatrixOnGPU2D <<<(256,128), (16,32)>>> elapsed 0.003902 ms
➜ chapter03 ./sumMatrix 16 16
sumMatrixOnGPU2D <<<(256,256), (16,16)>>> elapsed 0.003748 ms一个内核的可实现占用率被定义为:每周期内活跃线程束的平均数量与一个SM支持的线程束最大数量的比值。因为第二种情况中的块数比第一种情况的多,所以设备就可以有更多活跃的线程束。其原因可能是第二种情况与第一种情况相比有更高的可实现占用率和更好的性能。第四种情况有最高的可实现占用率,但它不是最快的,因此,更高的占用率并不一定意味着有更高的性能。肯定有其他因素限制GPU的性能。(这里和orin上测试结果不一致)
3.3.2 用nvprof检测内存操作
在sumMatrix内核(C[idx]=A[idx]+B[idx])中有3个内存操作:两个内存加载和一个内存存储。
第四种情况中的加载吞吐量最高,第二种情况中的加载吞吐量大约是第四种情况的一半,但第四种情况却比第二种情况慢。所以,更高的加载吞吐量并不一定意味着更高的性能。最后两种情况下的加载效率是最前面两种情况的一半。这可以解释为什么最后两种情况下更高的加载吞吐量和可实现占用率没有产生较好的性能。尽管在最后两种情况下正在执行的加载数量(即吞吐量)很多,但是那些加载的有效性(即效率)是较低的。
最后两种情况的共同特征是它们在最内层维数中块的大小是线程束的一半。如前所述,对网格和块启发式算法来说,最内层的维数应该总是线程束大小的倍数。
3.3.3 增大并行性
从前一节可以总结出,一个块的最内层维数(block.x)应该是线程束大小的倍数。这样能极大地提高了加载效率。
➜ chapter03 ./sumMatrix 64 2
sumMatrixOnGPU2D <<<(64,2048), (64,2)>>> elapsed 0.003877 ms
➜ chapter03 ./sumMatrix 64 4
sumMatrixOnGPU2D <<<(64,1024), (64,4)>>> elapsed 0.003864 ms
➜ chapter03 ./sumMatrix 64 8
sumMatrixOnGPU2D <<<(64,512), (64,8)>>> elapsed 0.003923 ms
➜ chapter03 ./sumMatrix 128 2
sumMatrixOnGPU2D <<<(32,2048), (128,2)>>> elapsed 0.003818 ms
➜ chapter03 ./sumMatrix 128 4
sumMatrixOnGPU2D <<<(32,1024), (128,4)>>> elapsed 0.003972 ms
➜ chapter03 ./sumMatrix 128 8
sumMatrixOnGPU2D <<<(32,512), (128,8)>>> elapsed 0.005476 ms
➜ chapter03 ./sumMatrix 256 2
sumMatrixOnGPU2D <<<(16,2048), (256,2)>>> elapsed 0.003937 ms
➜ chapter03 ./sumMatrix 256 4
sumMatrixOnGPU2D <<<(16,1024), (256,4)>>> elapsed 0.006425 ms
➜ chapter03 ./sumMatrix 256 8
sumMatrixOnGPU2D <<<(16,512), (256,8)>>> elapsed 0.000010 ms
Error: sumMatrix.cu:140, code: 9, reason: invalid configuration argument- 最后一次的执行配置块的大小为(256,8),这是无效的。一个块中线程总数超过了1024个(这是GPU的硬件限制)。
- 最好的结果是第四种情况,块大小为(128,2)。
- 第一种情况中块大小为(64,2),尽管在这种情况下启动的线程块最多,但不是最快的配置。
- 因为第二种情况中块的配置为(64,4),与最好的情况有相同数量的线程块,这两种情况应该在设备上显示出相同的并行性。因为这种情况相比(128,2)仍然表现较差,所以你可以得出这样的结论:线程块最内层维度的大小对性能起着的关键的作用。这正重复了前一节中总结的结论。
- 在所有其他情况下,线程块的数量都比最好的情况少。因此,增大并行性仍然是性能优化的一个重要因素。
指标与性能
- 在大部分情况下,一个单独的指标不能产生最佳的性能
- 与总体性能最直接相关的指标或事件取决于内核代码的本质
- 在相关的指标与事件之间寻求一个好的平衡
- 从不同角度查看内核以寻找相关指标间的平衡
- 网格/块启发式算法为性能调节提供了一个很好的起点
3.4 避免分支分化
有时,控制流依赖于线程索引。线程束中的条件执行可能引起线程束分化,这会导致内核性能变差。通过重新组织数据的获取模式,可以减少或避免线程束分化。
3.4.1 并行归约问题
假设要对一个有N个元素的整数数组求和,如何通过并行计算快速求和呢?鉴于加法的结合律和交换律,数组元素可以以任何顺序求和。所以可以用以下的方法执行并行加法运算:
- 将输入向量划分到更小的数据块中。
- 用一个线程计算一个数据块的部分和。
- 对每个数据块的部分和再求和得出最终结果。
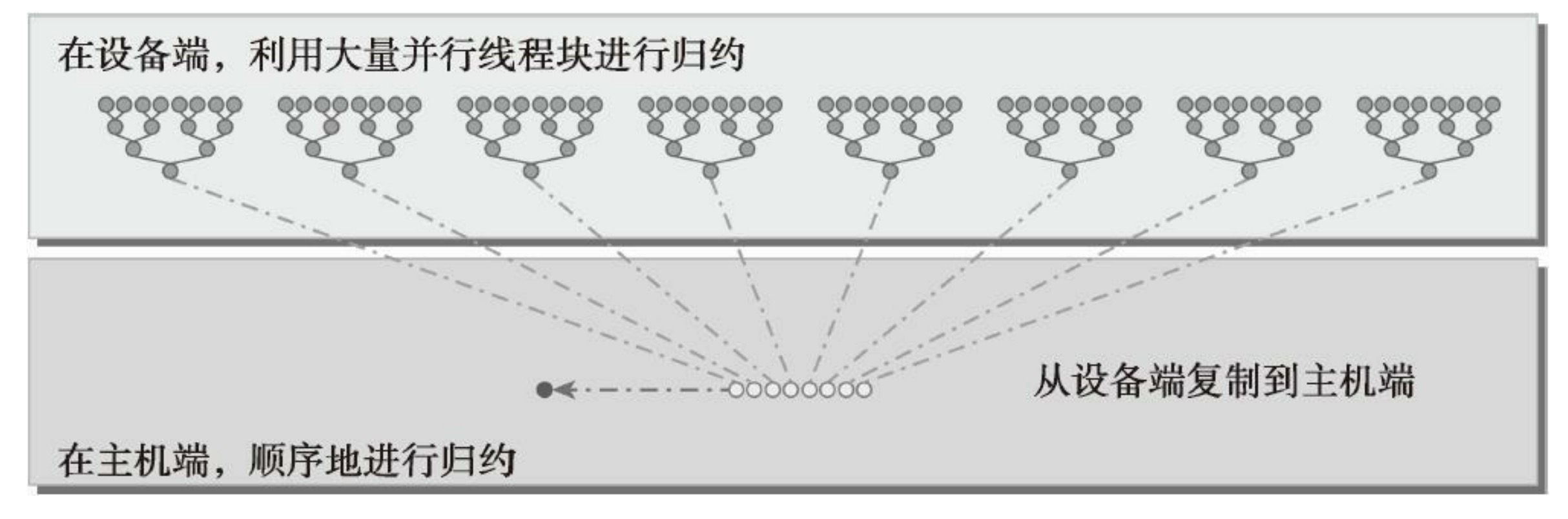
根据每次迭代后输出元素就地存储的位置,成对的并行求和实现可以被进一步分为以下两种类型:
- 相邻配对:元素与它们直接相邻的元素配对
- 交错配对:根据给定的跨度配对元素
在每一步实现中,一个线程对两个相邻元素进行操作,产生部分和。对于有N个元素的数组,这种实现方式需要N―1次求和,进行log2N步。值得注意的是,在这种实现方法的每一步中,一个线程的输入是输入数组长度的一半。
尽管以上实现的是加法,但任何满足交换律和结合律的运算都可以代替加法。例如,通过调用max代替求和运算,就可以计算输入向量中的最大值。其他有效运算的例子有最小值、平均值和乘积。在向量中执行满足交换律和结合律的运算,被称为归约问题。并行归约问题是这种运算的并行执行。并行归约是一种最常见的并行模式,并且是许多并行算法中的一个关键运算。
3.4.2 并行归约中的分化
在这个内核里,有两个全局内存数组:一个大数组用来存放整个数组,进行归约;另一个小数组用来存放每个线程块的部分和。每个线程块在数组的一部分上独立地执行操作。循环中迭代一次执行一个归约步骤。归约是在就地完成的,这意味着在每一步,全局内存里的值都被部分和替代。__syncthreads语句可以保证,线程块中的任一线程在进入下一次迭代之前,在当前迭代里每个线程的所有部分和都被保存在了全局内存中。进入下一次迭代的所有线程都使用上一步产生的数值。在最后一个循环以后,整个线程块的和被保存进全局内存中。
// Neighbored Pair Implementation with divergence
__global__ void reduceNeighbored (int *g_idata, int *g_odata, unsigned int n)
{
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
// boundary check
if (idx >= n) return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
idata[tid] += idata[tid + stride];
}
// synchronize within threadblock
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
// main
// initialization
int size = 1 << 24; // total number of elements to reduce
printf(" with array size %d ", size);
// execution configuration
int blocksize = 512; // initial block size
if(argc > 1)
{
blocksize = atoi(argv[1]); // block size from command line argument
}
dim3 block (blocksize, 1);
dim3 grid ((size + block.x - 1) / block.x, 1);
printf("grid %d block %d\n", grid.x, block.x);
// allocate host memory
size_t bytes = size * sizeof(int);
int *h_idata = (int *) malloc(bytes);
int *h_odata = (int *) malloc(grid.x * sizeof(int));
int *tmp = (int *) malloc(bytes);
// initialize the array
for (int i = 0; i < size; i++)
{
// mask off high 2 bytes to force max number to 255
h_idata[i] = (int)( rand() & 0xFF );
}
memcpy (tmp, h_idata, bytes);
double iStart, iElaps;
int gpu_sum = 0;
// allocate device memory
int *d_idata = NULL;
int *d_odata = NULL;
CHECK(cudaMalloc((void **) &d_idata, bytes));
CHECK(cudaMalloc((void **) &d_odata, grid.x * sizeof(int)));
// kernel 1: reduceNeighbored
CHECK(cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
iStart = seconds();
reduceNeighbored<<<grid, block>>>(d_idata, d_odata, size);
CHECK(cudaDeviceSynchronize());
iElaps = seconds() - iStart;
CHECK(cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int),
cudaMemcpyDeviceToHost));
gpu_sum = 0;
for (int i = 0; i < grid.x; i++) gpu_sum += h_odata[i];
printf("gpu Neighbored elapsed %f sec gpu_sum: %d <<<grid %d block "
"%d>>>\n", iElaps, gpu_sum, grid.x, block.x);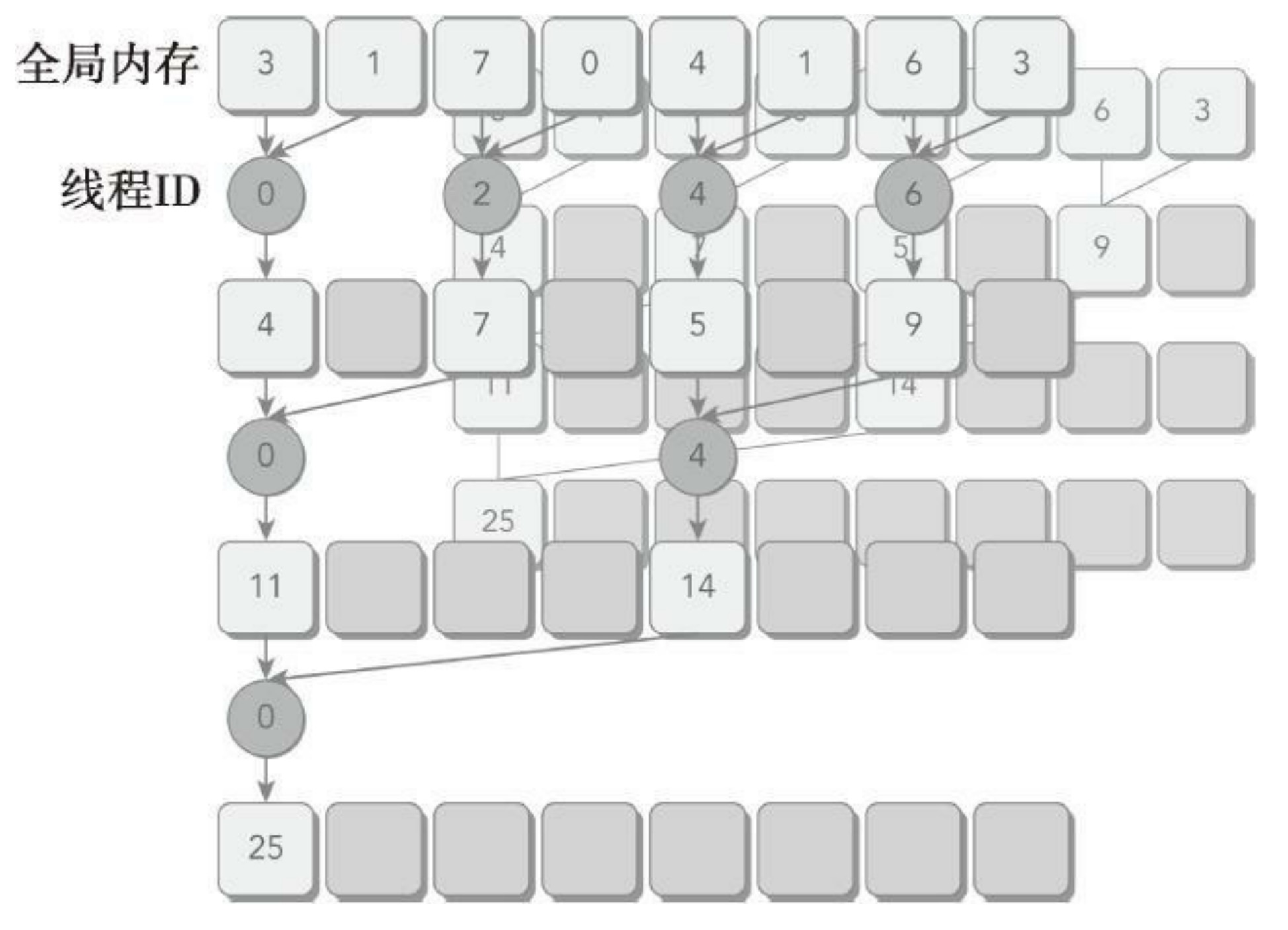
两个相邻元素间的距离被称为跨度,初始化均为1。在每一次归约循环结束后,这个间隔就被乘以2。在第一次循环结束后,idata(全局数据指针)的偶数元素将会被部分和替代。在第二次循环结束后,idata的每四个元素将会被新产生的部分和替代。因为线程块间无法同步,所以每个线程块产生的部分和被复制回了主机,并且在那儿进行串行求和。
reduceInteger.cu进行整数归约。
./reduceInteger starting reduction at device 0: Orin with array size 16777216 grid 32768 block 512
cpu reduce elapsed 0.081278 sec cpu_sum: 2139353471
gpu Neighbored elapsed 0.012773 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> # 基准数据
gpu Neighbored2 elapsed 0.006998 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
gpu Interleaved elapsed 0.006103 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>> # 交错归约
gpu Unrolling2 elapsed 0.003359 sec gpu_sum: 2139353471 <<<grid 16384 block 512>>>
gpu Unrolling4 elapsed 0.001816 sec gpu_sum: 2139353471 <<<grid 8192 block 512>>>
gpu Unrolling8 elapsed 0.001327 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
gpu UnrollWarp8 elapsed 0.001362 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
gpu Cmptnroll8 elapsed 0.001365 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
gpu Cmptnroll elapsed 0.001360 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>3.4.3 改善并行归约的分化
if ((tid % (2 * stride)) == 0)因为上述语句只对偶数ID的线程为true,所以这会导致很高的线程束分化。在并行归约的第一次迭代中,只有ID为偶数的线程执行这个条件语句的主体,但是所有的线程都必须被调度。在第二次迭代中,只有四分之一的线程是活跃的,但是所有的线程仍然都必须被调度。通过重新组织每个线程的数组索引来强制ID相邻的线程执行求和操作,线程束分化就能被归约了。和之前实现相比,部分和的存储位置并没有改变,但是工作线程已经更新了。注意看线程id不再是间隔的。
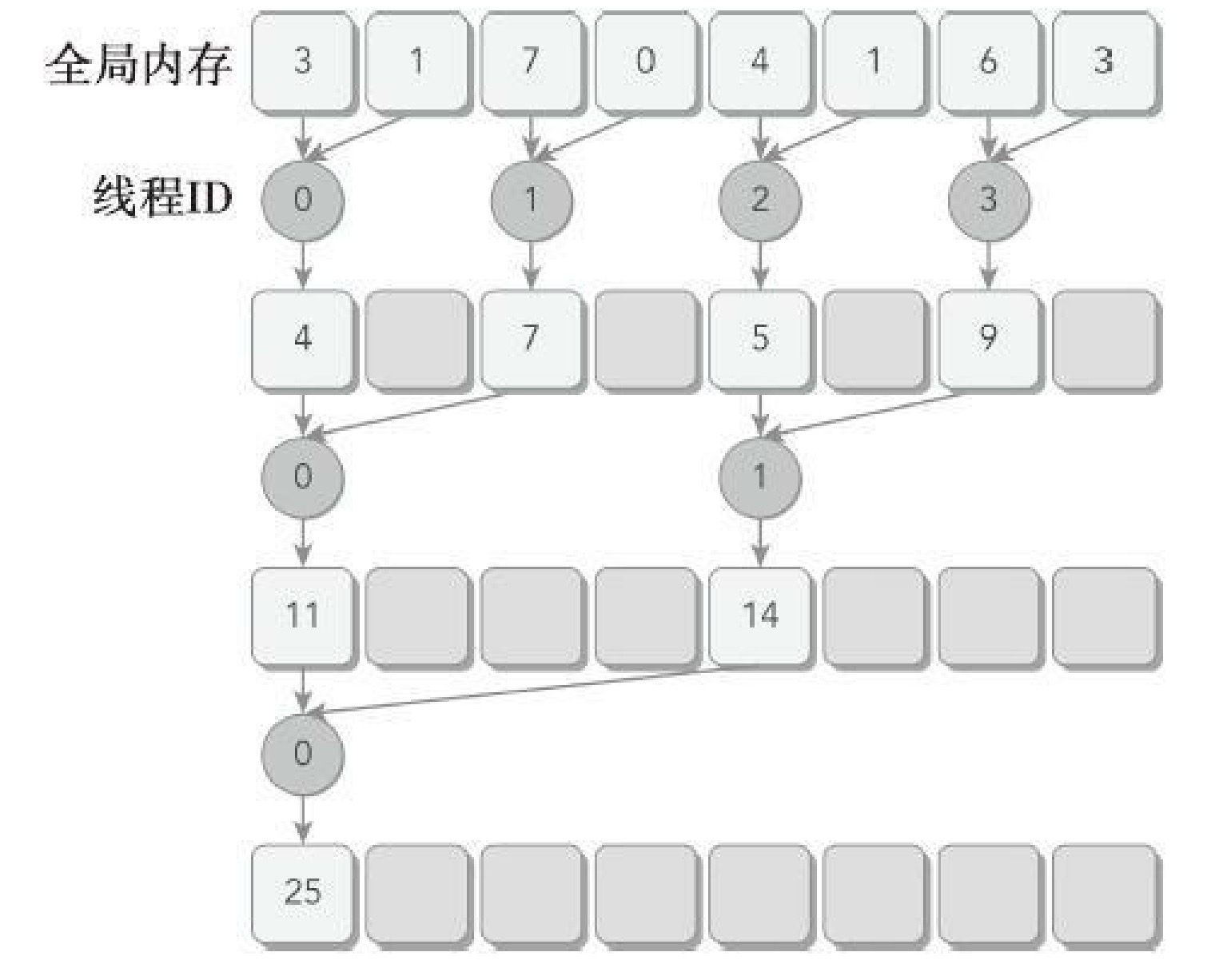
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
// convert tid into local array index
int index = 2 * stride * tid;
if (index < blockDim.x)
{
idata[index] += idata[index + stride];
}
// synchronize within threadblock
__syncthreads();
}因为跨度乘以了2,所以下面的语句使用线程块的前半部分来执行求和操作。
对于一个有512个线程(16个线程束)的块来说,前8个线程束执行第一轮归约,剩下8个线程束什么也不做。在第二轮里,前4个线程束执行归约,剩下12个线程束什么也不做。因此,这样就彻底不存在分化了。在最后五轮中,当每一轮的线程总数小于线程束的大小时,分化就会出现。在下一节将会介绍如何处理这一问题。
3.4.4 交错配对的归约
与相邻配对方法相比,交错配对方法颠倒了元素的跨度。初始跨度是线程块大小的一半,然后在每次迭代中减少一半。在每次循环中,每个线程对两个被当前跨度隔开的元素进行求和,以产生一个部分和。与上面改善并行归约案例相比,交错归约的工作线程没有变化。但是,每个线程在全局内存中的加载/存储位置是不同的。
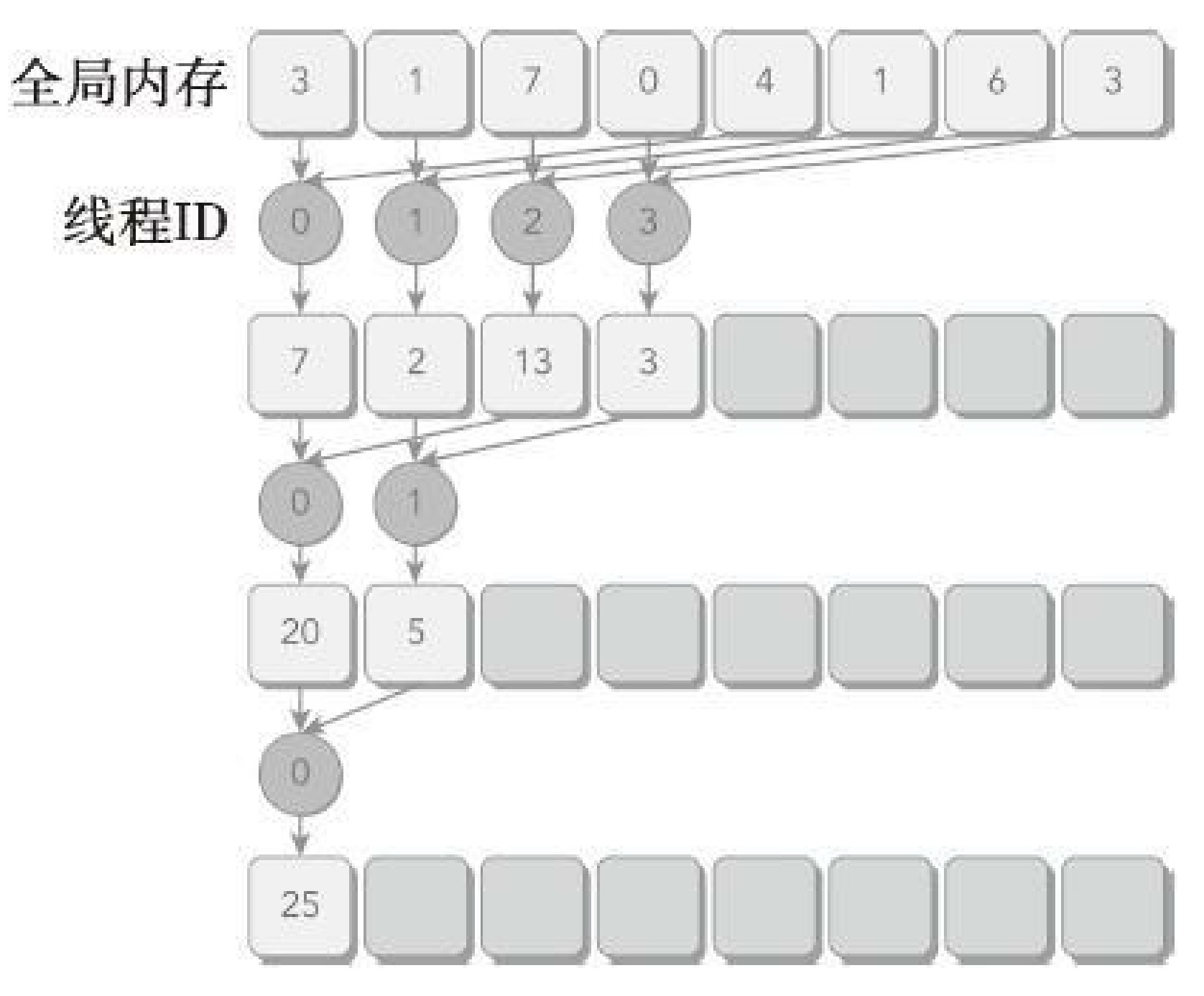
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid < stride)
{
idata[tid] += idata[tid + stride];
}
__syncthreads();
}3.5 展开循环
循环展开是一个尝试通过减少分支出现的频率和循环维护指令来优化循环的技术。在循环展开中,循环主体在代码中要多次被编写,而不是只编写一次循环主体再使用另一个循环来反复执行的。任何的封闭循环可将它的迭代次数减少或完全删除。循环体的复制数量被称为循环展开因子,迭代次数就变为了原始循环迭代次数除以循环展开因子。在顺序数组中,当循环的迭代次数在循环执行之前就已经知道时,循环展开是最有效提升性能的方法。例如:
for (int i = 0; i < 100; i ++){
a[i] = b[i] + c[i];
}
for (int i = 0; i < 100; i += 2){
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}从高级语言层面上来看,循环展开使性能提高的原因可能不是显而易见的。这种提升来自于编译器执行循环展开时低级指令的改进和优化。例如,在前面循环展开的例子中,条件i<100只检查了50次,而在原来的循环中则检查了100次。另外,因为在每个循环中每个语句的读和写都是独立的,所以CPU可以同时发出内存操作。在CUDA中,循环展开的意义非常重大。我们的目标仍然是相同的:通过减少指令消耗和增加更多的独立调度指令来提高性能。因此,更多的并发操作被添加到流水线上,以产生更高的指令和内存带宽。这为线程束调度器提供更多符合条件的线程束,它们可以帮助隐藏指令或内存延迟。
3.5.1 展开的归约
你可能会注意到,在reduceInterleaved核函数中每个线程块只处理一部分数据,这些数据可以被认为是一个数据块。如果用一个线程块手动展开两个数据块的处理,会怎么样?以下的核函数是reduceInterleaved核函数的修正版:每个线程块汇总了来自两个数据块的数据。这是一个循环分区(在第1章中已介绍)的例子,每个线程作用于多个数据块,并处理每个数据块的一个元素:
__global__ void reduceUnrolling2 (int *g_idata, int *g_odata, unsigned int n)
{
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 2;
// unrolling 2
if (idx + blockDim.x < n) g_idata[idx] += g_idata[idx + blockDim.x];
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid < stride)
{
idata[tid] += idata[tid + stride];
}
// synchronize within threadblock
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}注意要在核函数的开头添加的下述语句。在这里,每个线程都添加一个来自于相邻数据块的元素。从概念上来讲,可以把它作为归约循环的一个迭代,此循环可在数据块间归约:
if (idx + blockDim.x < n) g_idata[idx] += g_idata[idx + blockDim.x];因为现在每个线程块处理两个数据块,我们需要调整内核的执行配置,将网格大小减小至一半:
reduceUnrolling2<<<grid.x / 2, block>>>(d_idata, d_odata, size);即使只进行简单的更改,现在核函数的执行速度比原来快3.80倍。展开4次,提升7.03倍,展开8次,提升9.6倍。正如预想的一样,在一个线程中有更多的独立内存加载/存储操作会产生更好的性能,因为内存延迟可以更好地被隐藏起来。可以使用设备内存读取吞吐量指标,以确定这就是性能提高的原因。
3.5.2 展开线程的归约
__syncthreads是用于块内同步的。在归约核函数中,它用来确保在线程进入下一轮之前,每一轮中所有线程已经将局部结果写入全局内存中了。然而,要细想一下只剩下32个或更少线程(即一个线程束)的情况。因为线程束的执行是SIMT(单指令多线程)的,每条指令之后有隐式的线程束内同步过程。因此,归约循环的最后6个迭代可以用下述语句来展开:
// unrolling warp
if (tid < 32)
{
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}这个线程束的展开避免了执行循环控制和线程同步逻辑。注意变量vmem是和volatile修饰符一起被声明的,它告诉编译器每次赋值时必须将vmem[tid]的值存回全局内存中。如果省略了volatile修饰符,这段代码将不能正常工作,因为编译器或缓存可能对全局或共享内存优化读写。如果位于全局或共享内存中的变量有volatile修饰符,编译器会假定其值可以被其他线程在任何时间修改或使用。因此,任何参考volatile修饰符的变量强制直接读或写内存,而不是简单地读写缓存或寄存器。
3.5.3 完全展开的归约
如果编译时已知一个循环中的迭代次数,就可以把循环完全展开。因为在Fermi或Kepler架构中,每个块的最大线程数都是1024,并且在这些归约核函数中循环迭代次数是基于一个线程块维度的,所以完全展开归约循环是可能的。
3.5.4 模板函数的归约
虽然可以手动展开循环,但是使用模板函数有助于进一步减少分支消耗。在设备函数上CUDA支持模板参数。
template <unsigned int iBlockSize>
__global__ void reduceCompleteUnroll(int *g_idata, int *g_odata,
unsigned int n)
{
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
// unrolling 8
if (idx + 7 * blockDim.x < n)
{
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
// in-place reduction and complete unroll
if (iBlockSize >= 1024 && tid < 512) idata[tid] += idata[tid + 512];
__syncthreads();
if (iBlockSize >= 512 && tid < 256) idata[tid] += idata[tid + 256];
__syncthreads();
if (iBlockSize >= 256 && tid < 128) idata[tid] += idata[tid + 128];
__syncthreads();
if (iBlockSize >= 128 && tid < 64) idata[tid] += idata[tid + 64];
__syncthreads();
// unrolling warp
if (tid < 32)
{
volatile int *vsmem = idata;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
// main
switch (blocksize)
{
case 1024:
reduceCompleteUnroll<1024><<<grid.x / 8, block>>>(d_idata, d_odata,
size);
break;
case 512:
reduceCompleteUnroll<512><<<grid.x / 8, block>>>(d_idata, d_odata,
size);
break;
case 256:
reduceCompleteUnroll<256><<<grid.x / 8, block>>>(d_idata, d_odata,
size);
break;
case 128:
reduceCompleteUnroll<128><<<grid.x / 8, block>>>(d_idata, d_odata,
size);
break;
case 64:
reduceCompleteUnroll<64><<<grid.x / 8, block>>>(d_idata, d_odata, size);
break;
}相比reduceCompleteUnrollWarps8,唯一的区别是使用了模板参数替换了块大小。检查块大小的if语句将在编译时被评估,如果这一条件为false,那么编译时它将会被删除,使得内循环更有效率。例如,在线程块大小为256的情况下调用这个核函数,下述语句将永远是false,编译器会自动从执行内核中移除它。
iBlockSize >= 1024 && tid < 512该核函数一定要在switch-case结构中被调用。这允许编译器为特定的线程块大小自动优化代码,但这也意味着它只对在特定块大小下启动reduceCompleteUnroll有效。
注意,最大的相对性能增益是通过reduceUnrolling8核函数获得的,在这个函数之中每个线程在归约前处理8个数据块。有了8个独立的内存访问,可以更好地让内存带宽饱和及隐藏加载/存储延迟。
3.6 动态并行
CUDA的动态并行允许在GPU端直接创建和同步新的GPU内核。在一个核函数中在任意点动态增加GPU应用程序的并行性,是一个令人兴奋的新功能。到目前为止,我们需要把算法设计为单独的、大规模数据并行的内核启动。动态并行提供了一个更有层次结构的方法,在这个方法中,并发性可以在一个GPU内核的多个级别中表现出来。使用动态并行可以让递归算法更加清晰易懂,也更容易理解。有了动态并行,可以推迟到运行时决定需要在GPU上创建多少个块和网格,可以动态地利用GPU硬件调度器和加载平衡器,并进行调整以适应数据驱动或工作负载。在GPU端直接创建工作的能力可以减少在主机和设备之间传输执行控制和数据的需求,因为在设备上执行的线程可以在运行时决定启动配置
3.6.1 嵌套执行
在动态并行中,内核执行分为两种类型:父母和孩子。父线程、父线程块或父网格启动一个新的网格,即子网格。子线程、子线程块或子网格被父母启动。子网格必须在父线程、父线程块或父网格完成之前完成。只有在所有的子网格都完成之后,父母才会完成。
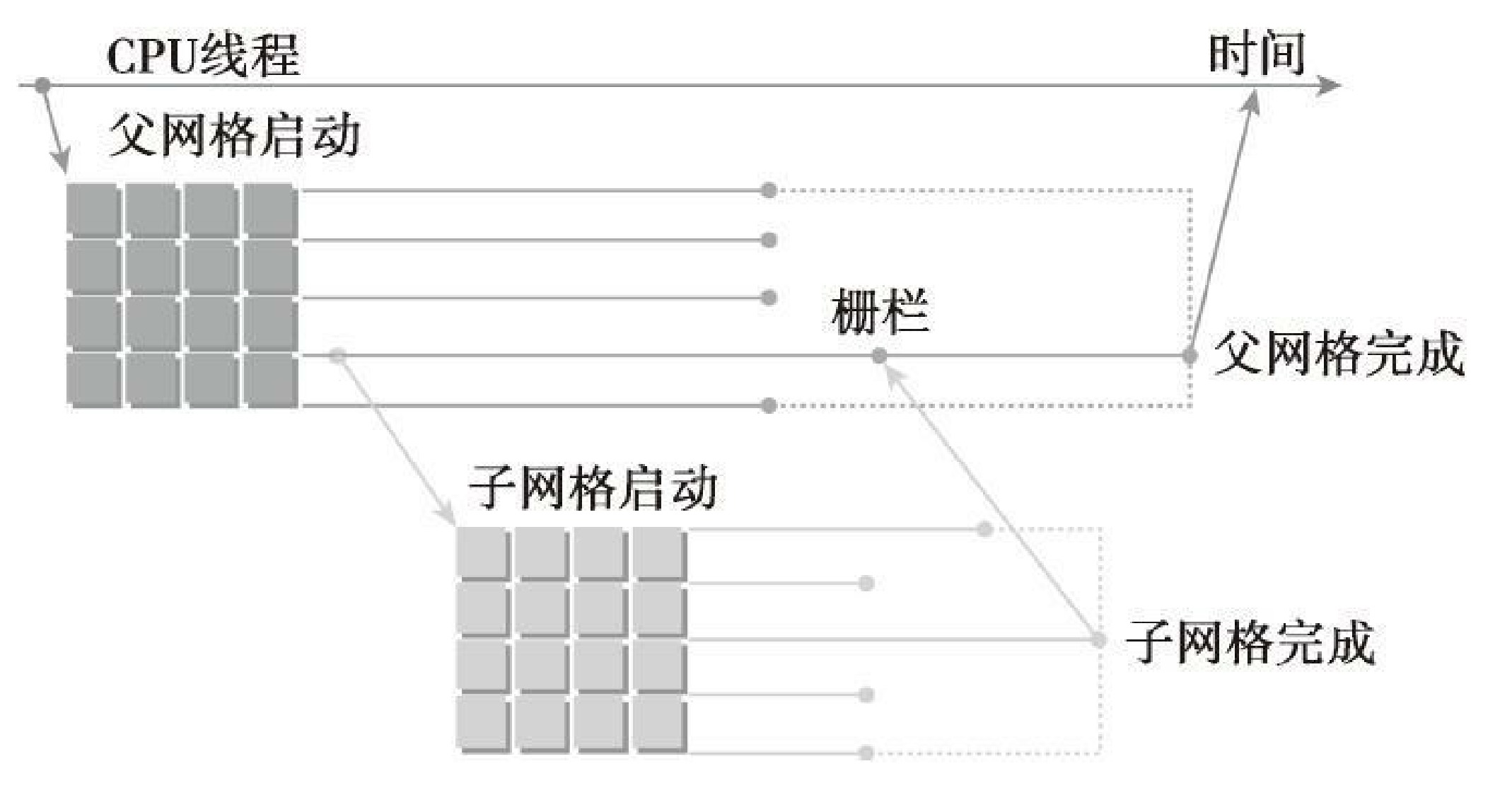
上图说明了父网格和子网格的适用范围。主机线程配置和启动父网格,父网格配置和启动子网格。子网格的调用和完成必须进行适当地嵌套,这意味着在线程创建的所有子网格都完成之后,父网格才会完成。如果调用的线程没有显式地同步启动子网格,那么运行时保证父母和孩子之间的隐式同步。在图中,在父线程中设置了栅栏,从而可以与其子网格显式地同步。
设备线程中的网格启动,在线程块间是可见的。这意味着,线程可能与由该线程启动的或由相同线程块中其他线程启动的子网格同步。在线程块中,只有当所有线程创建的所有子网格完成之后,线程块的执行才会完成。如果块中所有线程在所有的子网格完成之前退出,那么在那些子网格上隐式同步会被触发。
当父母启动一个子网格,父线程块与孩子显式同步之后,孩子才能开始执行。
父网格和子网格共享相同的全局和常量内存存储,但它们有不同的局部内存和共享内存。有了孩子和父母之间的弱一致性作为保证,父网格和子网格可以对全局内存并发存取。有两个时刻,子网格和它的父线程见到的内存完全相同:子网格开始时和子网格完成时。当父线程优于子网格调用时,所有的全局内存操作要保证对子网格是可见的。当父母在子网格完成时进行同步操作后,子网格所有的内存操作应保证对父母是可见的。
共享内存和局部内存分别对于线程块或线程来说是私有的,同时,在父母和孩子之间不是可见或一致的。局部内存对线程来说是私有存储,并且对该线程外部不可见。当启动一个子网格时,向局部内存传递一个指针作为参数是无效的。
3.6.2 在GPU上嵌套Hello World
为了初步理解动态并行,可以创建一个核函数,使其用动态并行来输出“Hello World”。nestedHelloWorld.cu主机应用程序调用父网格,该父网格在一个线程块中有8个线程。然后,该父网格中的线程0调用一个子网格,该子网格中有一半线程,即4个线程。之后,第一个子网格中的线程0再调用一个新的子网格,这个新的子网格中也只有一半线程,即2个线程,以此类推,直到最后的嵌套中只剩下一个线程。
因为动态并行是由设备运行时库所支持的,所以nestedHelloWorld函数必须在命令行使用-lcudadevrt进行明确链接。当-rdc标志为true时,它强制生成可重定位的设备代码,这是动态并行的一个要求。在本书的第10章将会介绍到更多可重定位设备代码的内容。动态并行只有在计算能力为3.5或更高的设备上才能被支持。通过动态并行调用的内核不能在物理方面独立的设备上启动。然而,在系统中允许查询任一个带CUDA功能的设备性能。动态并行的最大嵌套深度限制为24,但是实际上,在每一个新的级别中大多数内核受限于设备运行时系统需要的内存数量。因为为了对每个嵌套层中的父网格和子网格之间进行同步管理,设备运行时要保留额外的内存。
3.6.3 嵌套归约
归约可以被表示为一个递归函数。本章中的3.4节已经用C语言演示了递归归约。在CUDA里使用动态并行,可以确保CUDA里的递归归约核函数的实现像在C语言中一样简单。nestedReduce.cu 列出了带有动态并行的递归归约的内核代码。这个核函数原始的网格包含许多线程块,但所有嵌套的子网格中只有一个由其父网格的线程0调用的线程块。核函数的第一步是将全局内存地址g_idata转换为每个线程块的本地地址。接着,如果满足停止条件(这是指如果该条件是嵌套执行树上的叶子),结果就被拷贝回全局内存,并且控制立刻返回到父内核中。如果它不是一片叶子内核,就需要计算本地归约的大小,一半的线程执行就地归约。在就地归约完成后,同步线程块以保证所有部分和的计算。紧接着,线程0产生一个只有一个线程块和一个当前线程块一半线程数量的子网格。在子网格被调用后,所有子网格会设置一个障碍点。因为在每个线程块里,一个线程只产生一个子网格,所以这个障碍点只会同步一个子网格。
正如输出结果显示,最初有2048个线程块。因为每个线程块执行8次递归,所以总共创建了16384个子线程块,用于同步线程块内部的__syncthreads函数也被调用了16384次。如此大量的内核调用与同步很可能是造成内核效率很低的主要原因。
当一个子网格被调用后,它看到的内存与父线程是完全一样的。因为每一个子线程只需要父线程的数值来指导部分归约,所以在每个子网格启动前执行线程块内部的同步是没有必要的。去除所有同步操作会产生如下的核函数:nestedReduceNosync.cu。
然而,相较于相邻配对内核,它的性能仍然很差。需要考虑如何减少由大量的子网格启动引起的消耗。在当前的实现中,每个线程块产生一个子网格,并且引起了大量的调用。当创建的子网格数量减少时,那么每个子网格中线程块的数量将会增加,以保持相同数量的并行性。以下的 nestedReduce2.cu 实现了这种方法:网格中第一个线程块中的第一个线程在每一步嵌套时都调用子网格。比较这两个核函数的特征码,会发现多了一个参数。因为每次嵌套调用时,子线程块大小会减到其父线程块大小的一半,父线程块的维度也必须传递给嵌套的子网格。这使得每个线程都能为它的工作负载部分正确计算出消耗部分的全局内存偏移地址。值得注意的是,在这个实现中,所有空闲的线程都是在每次内核启动时被移除的,而对于第一次实现而言,在每个嵌套层的内核执行过程中都会有一半的线程空闲下来。这样的改变将会释放一半的被第一个核函数消耗的计算资源,这样可以让更多的线程块活跃起来。
该递归归约的例子说明了动态并行。对于一个给定的算法,通过使用不同的动态并行技术,可以有多种可能的实现方式。避免大量嵌套调用有助于减少消耗并提升性能。同步对性能与正确性都至关重要,但减少线程块内部的同步次数可能会使嵌套内核效率更高。因为在每一个嵌套层上设备运行时系统都要保留额外的内存,所以内核嵌套的最大数量可能是受限制的。这种限制的程度依赖于内核,也可能会限制任何使用动态并行应用程序的扩展、性能以及其他的性能。
3.7 总结
在GPU设备上,CUDA执行模型有两个最显著的特性:
- 使用SIMT方式在线程束中执行线程
- 在线程块与线程中分配了硬件资源
第4章 全局内存
本章将介绍CUDA内存模型,并通过分析不同的全局内存访问模式来教你如何通过核函数高效地利用全局内存。
4.1 CUDA内存模型概述
CUDA内存模型结合了主机和设备的内存系统,展现了完整的内存层次结构,使你能显式地控制数据布局以优化性能。
4.1.1 内存层次结构的优点
一般来说,应用程序不会在某一时间点访问任意数据或运行任意代码。应用程序往往遵循局部性原则,这表明它们可以在任意时间点访问相对较小的局部地址空间。有两种不同类型的局部性:
- 时间局部性,时间局部性认为如果一个数据位置被引用,那么该数据在较短的时间周期内很可能会再次被引用,随着时间流逝,该数据被引用的可能性逐渐降低。
- 空间局部性,空间局部性认为如果一个内存位置被引用,则附近的位置也可能会被引用。
通常,随着从处理器到内存延迟的增加,内存的容量也在增加。存储类型通常有如下特点:
- 更低的每比特位的平均成本
- 更高的容量
- 更高的延迟
- 更少的处理器访问频率
CPU和GPU的主存都采用的是DRAM(动态随机存取存储器),而低延迟内存(如CPU一级缓存)使用的则是SRAM(静态随机存取存储器)。GPU与CPU在内存层次结构设计中都使用相似的准则和模型。GPU和CPU内存模型的主要区别是,CUDA编程模型能将内存层次结构更好地呈现给用户,能让我们显式地控制它的行为。
4.1.2 CUDA内存模型
对于程序员来说,一般有两种类型的存储器:
- 可编程的:需要显式地控制哪些数据存放在可编程内存中
- 不可编程的:不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
在CPU内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。另一方面,CUDA内存模型提出了多种可编程内存的类型:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
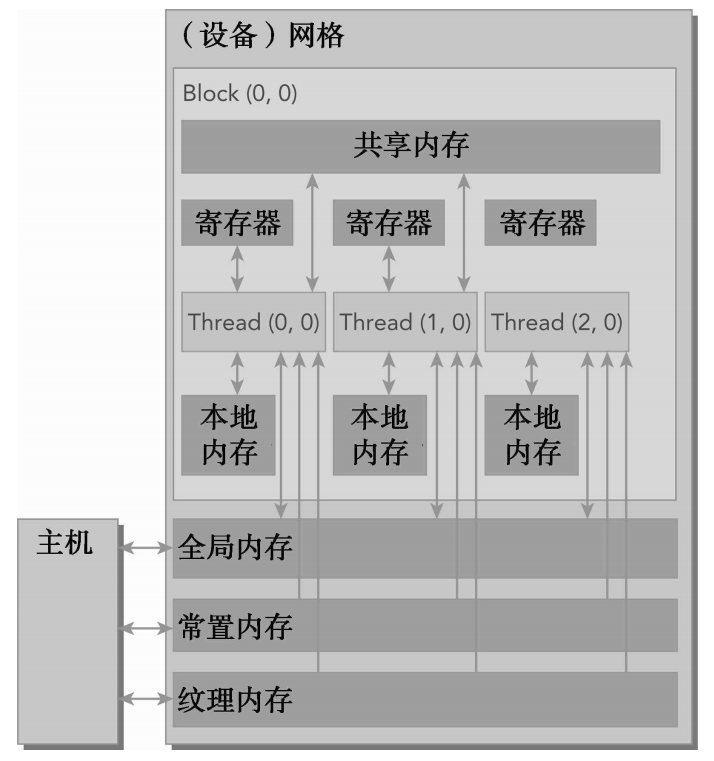
这些内存空间的层次结构,每种都有不同的作用域、生命周期和缓存行为。
- 一个核函数中的线程都有自己私有的本地内存。
- 一个线程块有自己的共享内存,对同一线程块中所有线程都可见,其内容持续线程块的整个生命周期。
- 所有线程都可以访问全局内存。
- 所有线程都能访问的只读内存空间有:常量内存空间和纹理内存空间。
- 全局内存、常量内存和纹理内存空间有不同的用途。纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。对于一个应用程序来说,全局内存、常量内存和纹理内存中的内容具有相同的生命周期。
4.1.2.1 寄存器
寄存器是GPU上运行速度最快的内存空间。核函数中声明的一个没有其他修饰符的自变量,通常存储在寄存器中。在核函数声明的数组中,如果用于引用该数组的索引是常量且能在编译时确定,那么该数组也存储在寄存器中。寄存器变量对于每个线程来说都是私有的,一个核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同。一旦核函数执行完毕,就不能对寄存器变量进行访问了。
寄存器是一个在SM中由活跃线程束划分出的较少资源。在Fermi GPU中,每个线程限制最多拥有63个寄存器。Kepler GPU将该限制扩展至每个线程可拥有255个寄存器。在核函数中使用较少的寄存器将使在SM上有更多的常驻线程块。每个SM上并发线程块越多,使用率和性能就越高。
如果一个核函数使用了超过硬件限制数量的寄存器,则会用本地内存替代多占用的寄存器。这种寄存器溢出会给性能带来不利影响。nvcc编译器使用启发式策略来最小化寄存器的使用,以避免寄存器溢出。我们也可以在代码中为每个核函数显式地加上额外的信息来帮助编译器进行优化:
__global__ void
__launch_bounds__(maxThreadPerBlock, minBlocksPerMultiprocessor)
kernel(...) {
// your kernel
}maxThreadsPerBlock指出了每个线程块可以包含的最大线程数,这个线程块由核函数来启动。minBlockPerMultiprocessor是可选参数,指明了在每个SM中预期的最小的常驻线程块数量。对于给定的核函数,最优的启动边界会因主要架构的版本不同而有所不同。你还可以使用maxrregcount编译器选项,来控制一个编译单元里所有核函数使用的寄存器的最大数量。
-maxregcount = 324.1.2.2 本地内存
核函数中符合存储在寄存器中但不能进入被该核函数分配的寄存器空间中的变量将溢出到本地内存中。编译器可能存放到本地内存中的变量有:
- 在编译时使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地结构体或数组
- 任何不满足核函数寄存器限定条件的变量
“本地内存”这一名词是有歧义的:溢出到本地内存中的变量本质上与全局内存在同一块存储区域,因此本地内存访问的特点是高延迟和低带宽,并且如在本章后面的4.3节中所描述的那样,本地内存访问符合高效内存访问要求。对于计算能力2.0及以上的GPU来说,本地内存数据也是存储在每个SM的一级缓存和每个设备的二级缓存中。
4.1.2.3 共享内存
在核函数中使用__shared__修饰符修饰的变量存放在共享内存中:因为共享内存是片上内存,所以与本地内存或全局内存相比,它具有更高的带宽和更低的延迟。它的使用类似于CPU一级缓存,但它是可编程的。每一个SM都有一定数量的由线程块分配的共享内存。因此,必须非常小心不要过度使用共享内存,否则将在不经意间限制活跃线程束的数量。
共享内存在核函数的范围内声明,其生命周期伴随着整个线程块。当一个线程块执行结束后,其分配的共享内存将被释放并重新分配给其他线程块。共享内存是线程之间相互通信的基本方式。一个块内的线程通过使用共享内存中的数据可以相互合作。访问共享内存必须同步使用如下调用,该命令是在之前章节中介绍过的CUDA运行时调用:
void __syncthreads();该函数设立了一个执行障碍点,即同一个线程块中的所有线程必须在其他线程被允许执行前达到该处。为线程块里所有线程设立障碍点,这样可以避免潜在的数据冲突。当一组未排序的多重访问通过不同的线程访问相同的内存地址时,这些访问中至少有一个是可写的,这时就会出现数据冲突。_syncthreads也会通过频繁强制SM到空闲状态来影响性能。SM中的一级缓存和共享内存都使用64KB的片上内存,它通过静态划分,但在运行时可以通过如下指令进行动态配置:
// 这个函数在每个核函数的基础上配置了片上内存划分,为func指定的核函数设置了配置。
cudaError_t cudaFuncSetCacheConfig(const void* func, enum cudaFuncCache cacheConfig);支持的缓存配置见:cudaFuncCache
4.1.2.4 常量内存
常量内存驻留在设备内存中,并在每个SM专用的常量缓存中缓存。常量变量用__constant__修饰符来修饰:常量变量必须在全局空间内和所有核函数之外进行声明。对于所有计算能力的设备,都只可以声明64KB的常量内存。常量内存是静态声明的,并对同一编译单元中的所有核函数可见。核函数只能从常量内存中读取数据。因此,常量内存必须在主机端使用下面的函数来初始化:
// 这个函数将 count 个字节从 src 指向的内存复制到 symbol 指向的内存中,这个变量存放在设备的
// 全局内存或常量内存中。在大多数情况下这个函数是同步的。线程束中的所有线程从相同的内存地址中读
// 取数据时,常量内存表现最好。举个例子,数学公式中的系数就是一个很好的使用常量内存的例子,因为
// 一个线程束中所有的线程使用相同的系数来对不同数据进行相同的计算。如果线程束里每个线程都从不同
// 的地址空间读取数据,并且只读一次,那么常量内存中就不是最佳选择,因为每从一个常量内存中读取一
// 次数据,都会广播给线程束里的所有线程。
__host__ cudaError_t cudaMemcpyToSymbol(const void* symbol,
const void* src,
size_t count,
size_t offset = 0,
cudaMemcpyKind kind = cudaMemcpyHostToDevice)4.1.2.5 纹理内存
纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存。纹理内存是一种通过指定的只读缓存访问的全局内存。只读缓存包括硬件滤波的支持,它可以将浮点插入作为读过程的一部分来执行。纹理内存是对二维空间局部性的优化,所以线程束里使用纹理内存访问二维数据的线程可以达到最优性能。对于一些应用程序来说,这是理想的内存,并由于缓存和滤波硬件的支持所以有较好的性能优势。然而对于另一些应用程序来说,与全局内存相比,使用纹理内存更慢。
4.1.2.6 全局内存
全局内存是GPU中最大、延迟最高并且最常使用的内存。global 指的是其作用域和生命周期。它的声明可以在任何SM设备上被访问到,并且贯穿应用程序的整个生命周期。一个全局内存变量可以被静态声明或动态声明。你可以使用__device__修饰符在设备代码中静态地声明一个变量。
从多个线程访问全局内存时必须注意。因为线程的执行不能跨线程块同步,不同线程块内的多个线程并发地修改全局内存的同一位置可能会出现问题,这将导致一个未定义的程序行为。全局内存常驻于设备内存中,可通过32字节、64字节或128字节的内存事务进行访问。这些内存事务必须自然对齐,也就是说,首地址必须是32字节、64字节或128字节的倍数。优化内存事务对于获得最优性能来说是至关重要的。当一个线程束执行内存加载/存储时,需要满足的传输数量通常取决于以下两个因素:
- 跨线程的内存地址分布
- 每个事务内存地址的对齐方式
4.1.2.7 GPU缓存
跟CPU缓存一样,GPU缓存是不可编程的内存。在GPU上有4种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个SM都有一个一级缓存,所有的SM共享一个二级缓存。一级和二级缓存都被用来在存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。对Fermi GPU和Kepler K40或其后发布的GPU来说,CUDA允许我们配置读操作的数据是使用一级和二级缓存,还是只使用二级缓存。
在CPU上,内存的加载和存储都可以被缓存。但是,在GPU上只有内存加载操作可以被缓存,内存存储操作不能被缓存。每个SM也有一个只读常量缓存和只读纹理缓存,它们用于在设备内存中提高来自于各自内存空间内的读取性能。
4.1.2.8 CUDA变量声明总结
| 修饰符 | 名称 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
| float var | 寄存器 | 线程 | 线程 | |
| float var[100] | 本地内存 | 线程 | 线程 | |
__shared__ |
float var* | 共享内存 | 块 | 块 |
__device__ |
float var* | 全局内存 | 全局 | 应用程序 |
__constant__ |
float var* | 常量内存 | 全局 | 应用程序 |
4.1.2.9 静态全局内存
下面的代码说明了如何静态声明一个全局变量。如代码清单 globalVariable.cu 所示,一个浮点类型的全局变量在文件作用域内被声明。在核函数checkGolbal-Variable中,全局变量的值在输出之后,就发生了改变。在主函数中,全局变量的值是通过函数cudaMemcpyToSymbol初始化的。在执行完checkGlobalVariable函数后,全局变量的值被替换掉了。新的值通过使用cudaMemcpyFromSymbol函数被复制回主机。
4.2 内存管理
如何使用CUDA函数来显式地管理内存和数据移动:
- 分配和释放设备内存
- 在主机和设备之间传输数据
4.2.1 内存分配和释放
// 这个函数在设备上分配了count字节的全局内存,并用devptr指针返回该内存的地址。
// 所分配的内存支持任何变量类型,包括整型、浮点类型变量、布尔类型等。
__host__ __device__ cudaError_t cudaMalloc( void** devPtr, size_t size)
// 这个函数用存储在变量value中的值来填充从设备内存地址devPtr处开始的count字节。
__host__ cudaError_t cudaMemset(void* devPtr, int value, size_t count)
// 释放该内存空间
// 如果地址空间已经被释放,那么cudaFree也返回一个错误
__host__ __device__ cudaError_t cudaFree(void* devPtr)4.2.2 内存传输
// 数从主机向设备传输数据:
// 这个函数从内存位置src复制了count字节到内存位置dst。变量kind指定了复制的方向
// 这个函数在大多数情况下都是同步的
__host__ cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
/*
enum cudaMemcpyKind
cudaMemcpyHostToHost = 0
Host -> Host
cudaMemcpyHostToDevice = 1
Host -> Device
cudaMemcpyDeviceToHost = 2
Device -> Host
cudaMemcpyDeviceToDevice = 3
Device -> Device
cudaMemcpyDefault = 4
*/memTransfer.cu 展示了在主机和设备之间来回地传输数据。使用cudaMalloc分配全局内存,使用cudaMemcpy将数据传输给设备,传输方向由cudaMemcpyHostToDevice指定。然后使用cudaMemcpy将数据传回主机,方向由cudaMemcpyDeviceToHost指定。
GPU芯片和板载GDDR5 GPU内存之间的理论峰值带宽非常高,对于Fermi C2050 GPU来说为144GB/s。CPU和GPU之间通过PCIe Gen2总线相连,这种连接的理论带宽要低得多,为8GB/s(PCIeGen3总线最大理论限制值是16GB/s)。这种差距意味着如果管理不当的话,主机和设备间的数据传输会降低应用程序的整体性能。因此,CUDA编程的一个基本原则应是尽可能地减少主机与设备之间的传输。
4.2.3 固定内存
分配的主机内存默认是 pageable(可分页),它的意思也就是因页面错误导致的操作,该操作按照操作系统的要求将主机虚拟内存上的数据移动到不同的物理位置。虚拟内存给人一种比实际可用内存大得多的假象,就如同一级缓存好像比实际可用的片上内存大得多一样。GPU不能在可分页主机内存上安全地访问数据,因为当主机操作系统在物理位置上移动该数据时,它无法控制。当从可分页主机内存传输数据到设备内存时,CUDA驱动程序首先分配临时页面锁定的或固定的主机内存,将主机源数据复制到固定内存中,然后从固定内存传输数据给设备内存。
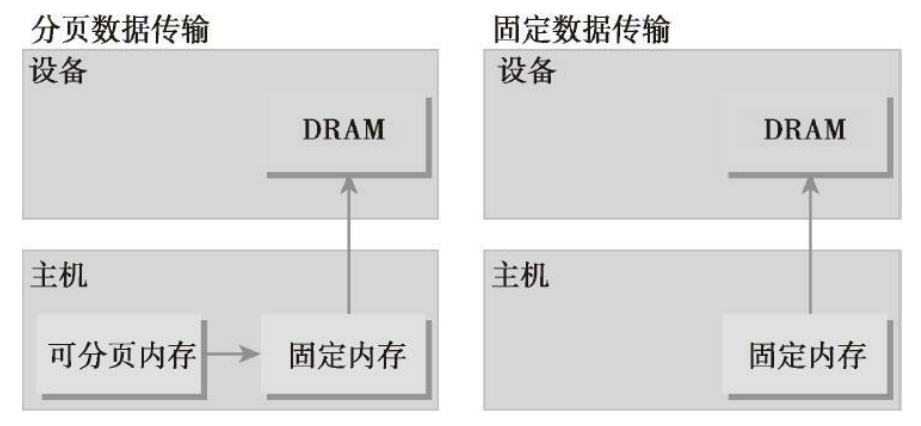
CUDA运行时允许你使用如下指令直接分配固定主机内存:
__host__ cudaError_t cudaMallocHost(void** ptr, size_t size)
__host__ cudaError_t cudaFreeHost(void* ptr)这个函数分配了count字节的主机内存,这些内存是页面锁定的并且对设备来说是可访问的。由于固定内存能被设备直接访问,所以它能用比可分页内存高得多的带宽进行读写。然而,分配过多的固定内存可能会降低主机系统的性能,因为它减少了用于存储虚拟内存数据的可分页内存的数量,其中分页内存对主机系统是可用的。
pinMemTransfer.cu 使用固定内存与使用memTransfer生成的输出相比性能提升了很多。与可分页内存相比,固定内存的分配和释放成本更高,但是它为大规模数据传输提供了更高的传输吞吐量。相对于可分页内存,使用固定内存获得的加速取决于设备计算能力。例如,当传输超过10MB的数据时,在Fermi设备上使用固定内存通常是更好的选择。将许多小的传输批处理为一个更大的传输能提高性能,因为它减少了单位传输消耗。主机和设备之间的数据传输有时可以与内核执行重叠。
4.2.4 零拷贝内存
通常来说,主机不能直接访问设备变量,同时设备也不能直接访问主机变量。但有一个例外:零拷贝内存。主机和设备都可以访问零拷贝内存。GPU线程可以直接访问零拷贝内存。在CUDA核函数中使用零拷贝内存有以下几个优势。
- 当设备内存不足时可利用主机内存
- 避免主机和设备间的显式数据传输
- 提高PCIe传输率
当使用零拷贝内存来共享主机和设备间的数据时,你必须同步主机和设备间的内存访问,同时更改主机和设备的零拷贝内存中的数据将导致不可预知的后果。零拷贝内存是固定(不可分页)内存,该内存映射到设备地址空间中。你可以通过下列函数创建一个到固定内存的映射:
/* Allocates page-locked memory on the host. */
// 这个函数分配了count字节的主机内存,该内存是页面锁定的且设备可访问的。
// 用这个函数分配的内存必须用cudaFreeHost函数释放。
_host__ cudaError_t cudaHostAlloc(void** pHost, size_t size, unsigned int flags)
__host__ cudaError_t cudaFreeHost(void* ptr)flags:
cudaHostAllocDefault函数使cudaHostAlloc函数的行为与cudaMallocHost函数一致。设置cudaHostAllocPortable函数可以返回能被所有CUDA上下文使用的固定内存,而不仅是执行内存分配的那一个。标志cudaHostAllocWriteCombined返回写结合内存,该内存可以在某些系统配置上通过PCIe总线上更快地传输,但是它在大多数主机上不能被有效地读取。因此,写结合内存对缓冲区来说是一个很好的选择,该内存通过设备使用映射的固定内存或主机到设备的传输。零拷贝内存的最明显的标志是cudaHostAllocMapped,该标志返回,可以实现主机写入和设备读取被映射到设备地址空间中的主机内存。
你可以使用下列函数获取映射到固定内存的设备指针:
/*
* Passes back device pointer of mapped host memory allocated
* by cudaHostAlloc or registered by cudaHostRegister.
*/
__host__cudaError_t cudaHostGetDevicePointer(void** pDevice,
void* pHost,
unsigned int flags)该函数返回了一个在pDevice中的设备指针,该指针可以在设备上被引用以访问映射得到的固定主机内存。如果设备不支持映射得到的固定内存,该函数将失效。flag将留作以后使用。现在,它必须被置为0。在进行频繁的读写操作时,使用零拷贝内存作为设备内存的补充将显著降低性能。因为每一次映射到内存的传输必须经过PCIe总线。与全局内存相比,延迟也显著增加。
sumArrayZerocopy.cu 主函数包含了两部分:第一部分为从设备内存加载数据及存储数据到设备内存;第二部分为从零拷贝内存加载数据,并将数据存储到设备内存中。开始时需要检查一下设备是否支持固定内存映射。为了允许核函数从零拷贝内存中读取数据,你需要将数组A和B分配作为映射的固定内存。然后可以直接在主机上初始化数组A和B,不需要将它们传输给设备内存。接下来获得了供核函数使用映射的固定内存的设备指针。一旦内存被分配并初始化就可以调用核函数了。从结果中可以看出,如果共享主机和设备端的少量数据,零拷贝内存可能会是一个不错的选择,因为它简化了编程并且有较好的性能。对于由PCIe总线连接的离散GPU上的更大数据集来说,零拷贝内存不是一个好的选择,它会导致性能的显著下降。
有两种常见的异构计算系统架构:集成架构和离散架构。在集成架构中,CPU和GPU集成在一个芯片上,并且在物理地址上共享主存。在这种架构中,由于无须在PCIe总线上备份,所以零拷贝内存在性能和可编程性方面可能更佳。对于通过PCIe总线将设备连接到主机的离散系统而言,零拷贝内存只在特殊情况下有优势。因为映射的固定内存在主机和设备之间是共享的,你必须同步内存访问来避免任何潜在的数据冲突,这种数据冲突一般是由多线程异步访问相同的内存而引起的。注意不要过度使用零拷贝内存。由于其延迟较高,从零拷贝内存中读取设备核函数可能很慢。
4.2.5 统一虚拟寻址
计算能力为2.0及以上版本的设备支持一种特殊的寻址方式,称为统一虚拟寻址(UVA)。UVA,在CUDA 4.0中被引入,支持64位Linux系统。有了UVA,主机内存和设备内存可以共享同一个虚拟地址空间,如图所示。在UVA之前,你需要管理哪些指针指向主机内存和哪些指针指向设备内存。有了UVA,由指针指向的内存空间对应用程序代码来说是透明的。通过UVA,由cudaHostAlloc分配的固定主机内存具有相同的主机和设备指针。因此,可以将返回的指针直接传递给核函数。
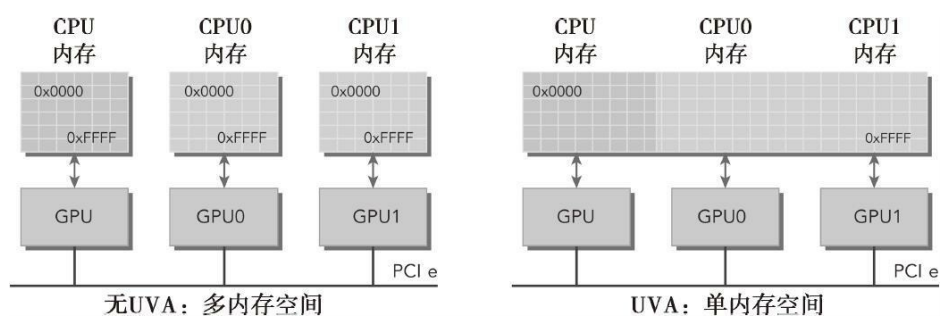
有了UVA,无须获取设备指针或管理物理上数据完全相同的两个指针。UVA会进一步简化前一节中的sumArrayZerocpy.cu示例:
// allocate zerocpy memory
CHECK(cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped));
CHECK(cudaHostAlloc((void **)&h_B, nBytes, cudaHostAllocMapped));
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
// invoke the kernel with zero-copy memory
sumArraysZeroCopy<<<grid, block>>>(h_A, h_B, d_C, nElem);执行与前一节相同的测试将产生相同的性能结果。使用更少的代码取得相同的结果,这提高了应用程序的可读性和可维护性。
4.2.6 统一内存寻址
在CUDA 6.0中,引入了“统一内存寻址”这一新特性,它用于简化CUDA编程模型中的内存管理。统一内存中创建了一个托管内存池,内存池中已分配的空间可以用相同的内存地址(即指针)在CPU和GPU上进行访问。底层系统在统一内存空间中自动在主机和设备之间进行数据传输。这种数据传输对应用程序是透明的,这大大简化了程序代码。统一内存寻址依赖于UVA的支持,但它们是完全不同的技术。UVA为系统中的所有处理器提供了一个单一的虚拟内存地址空间。但是,UVA不会自动将数据从一个物理位置转移到另一个位置,这是统一内存寻址的一个特有功能。统一内存寻址提供了一个“单指针到数据”模型,在概念上它类似于零拷贝内存。但是零拷贝内存在主机内存中进行分配,因此,由于受到在PCIe总线上访问零拷贝内存的影响,核函数的性能将具有较高的延迟。另一方面,统一内存寻址将内存和执行空间分离,因此可以根据需要将数据透明地传输到主机或设备上,以提升局部性和性能。
托管内存指的是由底层系统自动分配的统一内存,与特定于设备的分配内存可以互操作,如它们的创建都使用cudaMalloc程序。因此,你可以在核函数中使用两种类型的内存:由系统控制的托管内存,以及由应用程序明确分配和调用的未托管内存。所有在设备内存上有效的CUDA操作也同样适用于托管内存。其主要区别是主机也能够引用和访问托管内存。
托管内存可以被静态分配也可以被动态分配。可以通过添加__managed__注释,静态声明一个设备变量作为托管变量。但这个操作只能在文件范围和全局范围内进行。该变量可以从主机或设备代码中直接被引用:
__device__ __managed__ int y;还可以使用下述的CUDA运行时函数动态分配托管内存:
/* Allocates memory that will be automatically managed by the Unified Memory system. */
__host__ cudaError_t cudaMallocManaged(void** devPtr,
size_t size,
unsigned int flags = cudaMemAttachGlobal)这个函数分配size字节的托管内存,并用devPtr返回一个指针。该指针在所有设备和主机上都是有效的。使用托管内存的程序行为与使用未托管内存的程序副本行为在功能上是一致的。但是,使用托管内存的程序可以利用自动数据传输和重复指针消除功能。在CUDA 6.0中,设备代码不能调用cudaMallocManaged函数。所有的托管内存必须在主机端动态声明或者在全局范围内静态声明。
4.3 内存访问模式
大多数设备端数据访问都是从全局内存开始的,并且多数GPU应用程序容易受内存带宽的限制。因此,最大限度地利用全局内存带宽是调控核函数性能的基本。为了在读写数据时达到最佳的性能,内存访问操作必须满足一定的条件。CUDA执行模型的显著特征之一就是指令必须以线程束为单位进行发布和执行。存储操作也是同样。在执行内存指令时,线程束中的每个线程都提供了一个正在加载或存储的内存地址。在线程束的32个线程中,每个线程都提出了一个包含请求地址的单一内存访问请求,它并由一个或多个设备内存传输提供服务。根据线程束中内存地址的分布,内存访问可以被分成不同的模式。
4.3.1 对齐与合并访问
全局内存通过缓存来实现加载/存储。全局内存是一个逻辑内存空间,可以通过核函数访问它。所有的应用程序数据最初存在于DRAM上,即物理设备内存中。核函数的内存请求通常是在DRAM设备和片上内存间以128字节或32字节内存事务来实现的。
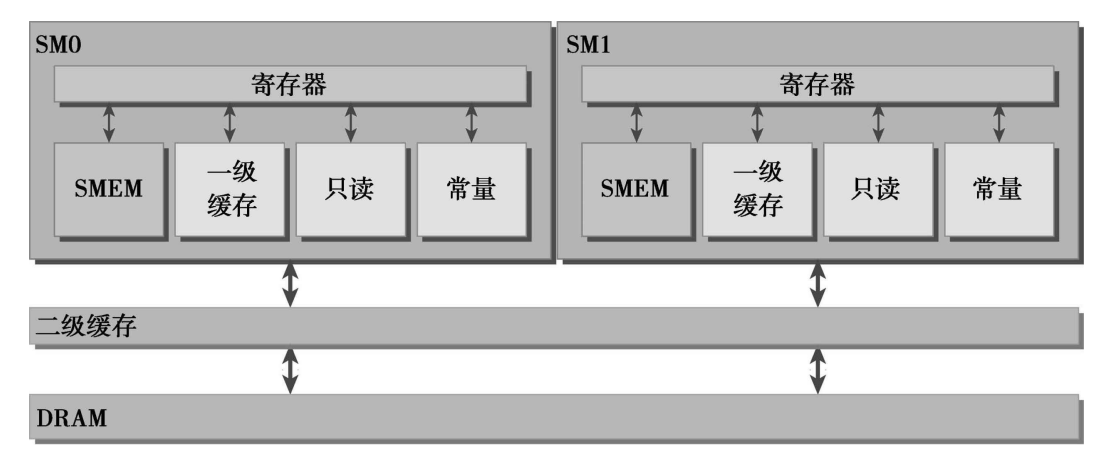
所有对全局内存的访问都会通过二级缓存,也有许多访问会通过一级缓存,这取决于访问类型和GPU架构。如果这两级缓存都被用到,那么内存访问是由一个128字节的内存事务实现的。如果只使用了二级缓存,那么这个内存访问是由一个32字节的内存事务实现的。对全局内存缓存其架构,如果允许使用一级缓存,那么可以在编译时选择启用或禁用一级缓存。一行一级缓存是128个字节,它映射到设备内存中一个128字节的对齐段。如果线程束中的每个线程请求一个4字节的值,那么每次请求就会获取128字节的数据,这恰好与缓存行和设备内存段的大小相契合。因此在优化应用程序时,你需要注意设备内存访问的两个特性:
- 对齐内存访问,当设备内存事务的第一个地址是用于事务服务的缓存粒度的偶数倍时(32字节的二级缓存或128字节的一级缓存),就会出现对齐内存访问。运行非对齐的加载会造成带宽浪费。
- 合并内存访问,当一个线程束中全部的32个线程访问一个连续的内存块时,就会出现合并内存访问。
对齐合并内存访问的理想状态是线程束从对齐内存地址开始访问一个连续的内存块。为了最大化全局内存吞吐量,为了组织内存操作进行对齐合并是很重要的。一般来说,需要优化内存事务效率:用最少的事务次数满足最多的内存请求。事务数量和吞吐量的需求随设备的计算能力变化。
4.3.2 全局内存读取
在SM中,数据通过以下3种缓存/缓冲路径进行传输,具体使用何种方式取决于引用了哪种类型的设备内存:
- 一级和二级缓存
- 常量缓存
- 只读缓存
一/二级缓存是默认路径。想要通过其他两种路径传递数据需要应用程序显式地说明,但要想提升性能还要取决于使用的访问模式。全局内存加载操作是否会通过一级缓存取决于两个因素:
- 设备的计算能力
- 编译器选项
-Xptxas -dlcm=cg标志通知编译器禁用一级缓存。如果一级缓存被禁用,所有对全局内存的加载请求将直接进入到二级缓存;如果二级缓存缺失,则由DRAM完成请求。每一次内存事务可由一个、两个或四个部分执行,每个部分有32个字节。一级缓存也可以使用标识符-Xptxas -dlcm=ca直接启用。设置这个标志后,全局内存加载请求首先尝试通过一级缓存。如果一级缓存缺失,该请求转向二级缓存。如果二级缓存缺失,则请求由DRAM完成。在这种模式下,一个内存加载请求由一个128字节的设备内存事务实现。
内存加载可以分为两类:
- 缓存加载(启用一级缓存)
- 没有缓存的加载(禁用一级缓存)
内存加载的访问模式有如下特点:
- 有缓存与没有缓存:如果启用一级缓存,则内存加载被缓存
- 对齐与非对齐:如果内存访问的第一个地址是32字节的倍数,则对齐加载
- 合并与未合并:如果线程束访问一个连续的数据块,则加载合并
4.3.2.1 缓存加载
缓存加载操作经过一级缓存,在粒度为128字节的一级缓存行上由设备内存事务进行传输。缓存加载可以分为对齐/非对齐及合并/非合并。为理想情况:对齐与合并内存访问。线程束中所有线程请求的地址都在128字节的缓存行范围内。完成内存加载操作只需要一个128字节的事务。总线的使用率为100%,在这个事务中没有未使用的数据。

另一种情况:访问是对齐的,引用的地址不是连续的线程ID,而是128字节范围内的随机值。由于线程束中线程请求的地址仍然在一个缓存行范围内,所以只需要一个128字节的事务来完成这一内存加载操作。总线利用率仍然是100%,并且只有当每个线程请求在128字节范围内有4个不同的字节时,这个事务中才没有未使用的数据。

线程束请求32个连续4个字节的非对齐数据元素。在全局内存中线程束的线程请求的地址落在两个128字节段范围内。因为当启用一级缓存时,由SM执行的物理加载操作必须在128个字节的界线上对齐,所以要求有两个128字节的事务来执行这段内存加载操作。总线利用率为50%,并且在这两个事务中加载的字节有一半是未使用的。

线程束中所有线程请求相同的地址。因为被引用的字节落在一个缓存行范围内,所以只需请求一个内存事务,但总线利用率非常低。如果加载的值是4字节的,则总线利用率是4字节请求/128字节加载=3.125%。

最坏的情况:线程束中线程请求分散于全局内存中的32个4字节地址。尽管线程束请求的字节总数仅为128个字节,但地址要占用N个缓存行(0<N≤32)。完成一次内存加载操作需要申请N次内存事务。

CPU一级缓存和GPU一级缓存之间的差异:CPU一级缓存优化了时间和空间局部性。GPU一级缓存是专为空间局部性而不是为时间局部性设计的。频繁访问一个一级缓存的内存位置不会增加数据留在缓存中的概率。
4.3.2.2 没有缓存的加载
没有缓存的加载不经过一级缓存,它在内存段的粒度上(32个字节)而非缓存池的粒度(128个字节)执行。这是更细粒度的加载,可以为非对齐或非合并的内存访问带来更好的总线利用率。理想情况:对齐与合并内存访问。128个字节请求的地址占用了4个内存段,总线利用率为100%。

内存访问是对齐的且线程访问是不连续的,而是在128个字节的范围内随机进行。只要每个线程请求唯一的地址,那么地址将占用4个内存段,并且不会有加载浪费。这样的随机访问不会抑制内核性能。

线程束请求32个连续的4字节元素但加载没有对齐到128个字节的边界。请求的地址最多落在5个内存段内,总线利用率至少为80%。与这些类型的请求缓存加载相比,使用非缓存加载会提升性能,这是因为加载了更少的未请求字节。

线程束中所有线程请求相同的数据。地址落在一个内存段内,总线的利用率是请求的4字节/加载的32字节=12.5%,在这种情况下,非缓存加载性能也是优于缓存加载的性能。

最坏的一种情况:线程束请求32个分散在全局内存中的4字节字。由于请求的128个字节最多落在N个32字节的内存分段内而不是N个128个字节的缓存行内,所以相比于缓存加载,即便是最坏的情况也有所改善。

4.3.2.3 非对齐读取的示例
jetson启用缓存:改为16MB
$ ./readSegment 0
readOffset <<< 32768, 512 >>> offset 0 elapsed 0.003483 sec
$ ./readSegment 11
readOffset <<< 32768, 512 >>> offset 11 elapsed 0.003507 sec
$ ./readSegment 128
readOffset <<< 32768, 512 >>> offset 128 elapsed 0.003478 sec
$ nvcc readSegment.cu -o readSegment -Xptxas -dlcm=cg
$ ./readSegment 0
readOffset <<< 32768, 512 >>> offset 0 elapsed 0.003470 sec
$ ./readSegment 11
readOffset <<< 32768, 512 >>> offset 11 elapsed 0.003610 sec
$ ./readSegment 128
readOffset <<< 32768, 512 >>> offset 128 elapsed 0.003514 secreadSegment.cu 新的索引k由给定的偏移量上移,由于偏移量的值可能会导致加载出现非对齐加载。只有加载数组A和数组B的操作会用到索引k。对数组C的写操作仍使用原来的索引i,以确保写入访问保持对齐。使用值为11的偏移量会导致数组A和数组B的内存加载是非对齐的。在这种情况下,运行时间也是最慢的。通过观察以全局加载效率为指标的结果,可以验证这些非对齐访问就是性能损失的原因:
$$
全局加载效率=\frac{请求的全局内存加载吞吐量}{所需的全局内存加载吞吐量}
$$
对于非对齐读取的情况(偏移量为11),全局加载效率减半,这意味着请求的全局内存加载吞吐量加倍。也可以看到禁用一级缓存对全局内存加载性能有何影响。结果显示,没有缓存的加载的整体性能略低于缓存访问的性能。缓存缺失对非对齐访问的性能影响更大。如果启用缓存,一个非对齐访问可能将数据存到一级缓存,这个一级缓存用于后续的非对齐内存访问。但是,如果没有一级缓存,那么每一次非对齐请求需要多个内存事务,并且对将来的请求没有作用。对于非对齐情况,禁用一级缓存使加载效率得到了提高,从49.8%提高到了80%。由于禁用了一级缓存,每个加载请求是在32个字节的粒度上而不是128个字节的粒度上进行处理,因此加载的字节(但未使用的)数量减少了。
4.3.2.4 只读缓存
只读缓存最初是预留给纹理内存加载使用的。对计算能力为3.5及以上的GPU来说,只读缓存也支持使用全局内存加载代替一级缓存。只读缓存的加载粒度是32个字节。通常,对分散读取来说,这些更细粒度的加载要优于一级缓存。有两种方式可以指导内存通过只读缓存进行读取:
- 使用函数
__ldg - 在间接引用的指针上使用修饰符
例如:
__global__ vopid copyKernel(int *out, int *in) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
out[idx] = __ldg(&in[idx]);
}可以将常量__restrict__修饰符应用到指针上。这些修饰符帮助nvcc编译器识别无别名指针(即专门用来访问特定数组的指针)。nvcc将自动通过只读缓存指导无别名指针的加载。
__global__ vopid copyKernel(int * __restrict__ out, const int * __restrict__ in) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
out[idx] = in[idx];
}4.3.3 全局内存写入
内存的存储操作相对简单。一级缓存不能用在Fermi或Kepler GPU上进行存储操作,在发送到设备内存之前存储操作只通过二级缓存。存储操作在32个字节段的粒度上被执行。内存事务可以同时被分为一段、两段或四段。例如,如果两个地址同属于一个128个字节区域,但是不属于一个对齐的64个字节区域,则会执行一个四段事务(也就是说,执行一个四段事务比执行两个一段事务效果更好)。理想情况:内存访问是对齐的,并且线程束里所有的线程访问一个连续的128字节范围。存储请求由一个四段事务实现。
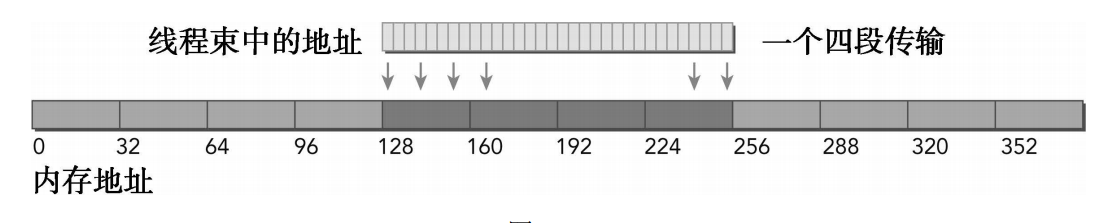
内存访问是对齐的,但地址分散在一个192个字节范围内的情况。存储请求由3个一段事务来实现。

内存访问是对齐的,并且地址访问在一个连续的64个字节范围内的情况。这种存储请求由一个两段事务来完成。

writeSegment.cu 使用两个不同的索引:索引k根据给定的偏移量进行变化,而索引i不变(并因此产生对齐访问)。使用对齐索引i从数组A和数组B中进行加载,以产生良好的内存加载效率。使用偏移量索引x写入数组C,可能会造成非对齐写入,这取决于偏移量的值。显然,非对齐写入的情况(偏移量为11)性能最差。除了非对齐情况(偏移量为11)的存储,所有加载和存储的效率都为100%。非对齐写入的存储效率为80%。当偏移量为11且从一个线程束产生一个128个字节的写入请求时,该请求将由一个四段事务和一个一段事务来实现。因此,128个字节用来请求,160个字节用来加载,存储效率为80%
# jstson 16M数据
$ ./writeSegment
writeOffset <<< 32768, 512 >>> offset 0 elapsed 0.003470 sec
unroll2 <<< 16384, 512 >>> offset 0 elapsed 0.002711 sec
unroll4 <<< 8192, 512 >>> offset 0 elapsed 0.002232 sec
$ ./writeSegment 11
writeOffset <<< 32768, 512 >>> offset 11 elapsed 0.003534 sec
unroll2 <<< 16384, 512 >>> offset 11 elapsed 0.003165 sec
unroll4 <<< 8192, 512 >>> offset 11 elapsed 0.002583 sec
$ ./writeSegment 128
writeOffset <<< 32768, 512 >>> offset 128 elapsed 0.003471 sec
unroll2 <<< 16384, 512 >>> offset 128 elapsed 0.002701 sec
unroll4 <<< 8192, 512 >>> offset 128 elapsed 0.002240 sec4.3.4 结构体数组与数组结构体
作为一个C程序员,你应该对两种数据组织方式非常熟悉:数组结构体(AoS)和结构体数组(SoA)。当存储结构化数据集时,它们代表了可以采用的两种强大的数据组织方式(结构体和数组)。下面是存储成对的浮点数据元素集的例子。首先,考虑这些成对数据元素集如何使用AoS方法进行存储。如下定义一个结构体,命名为innerStruct:
struct innerStruct {
float x;
float y;
}
// 按照下面的方法定义这些结构体数组。这是利用AoS方式来组织数据的。它存
// 储的是空间上相邻的数据(例如,x和y),这在CPU上会有良好的缓存局部性。
struct innerStruct myAos[N];考虑使用SoA方法来存储数据:
struct innerArray {
float x[N];
float y[N];
}
// 在原结构体中每个字段的所有值都被分到各自的数组中。这不仅能将相邻数据
// 点紧密存储起来,也能将跨数组的独立数据点存储起来。
struct innerArry mySoa;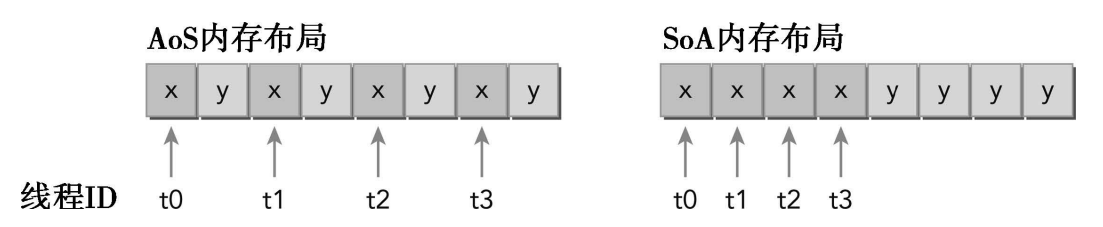
上图说明了AoS和SoA方法的内存布局。用AoS模式在GPU上存储示例数据并执行一个只有x字段的应用程序,将导致50%的带宽损失,因为y值在每32个字节段或128个字节缓存行上隐式地被加载。AoS格式也在不需要的y值上浪费了二级缓存空间。用SoA模式存储数据充分利用了GPU的内存带宽。由于没有相同字段元素的交叉存取,GPU上的SoA布局提供了合并内存访问,并且可以对全局内存实现更高效的利用。许多并行编程范式,尤其是SIMD型范式,更倾向于使用SoA。在CUDA C编程中也普遍倾向于使用SoA,因为数据元素是为全局内存的有效合并访问而预先准备好的,而被相同内存操作引用的同字段数据元素在存储时是彼此相邻的。在每种数据布局中为了帮助理解访问数据对性能的影响,我们将通过执行相同的数学运算来比较两个核函数:一个使用AoS数据布局,另一个则使用SoA数据布局。
示例代码: simpleMathAoS.cu 结果展示的50%的效率结果表明,对于AOS数据布局,加载请求和内存存储请求是重复的。因为字段x和y在内存中是被相邻存储的,并且有相同的大小,每当执行内存事务时都要加载特定字段的值,被加载的字节数的一半也必须属于其他字段。因此,请求加载和存储的50%带宽是未使用的。和 simpleMathSoA.cu 结果展示100%的效率,说明当处理SoA数据布局时,加载或存储内存请求不会重复。每次访问都由一个独立的内存事务来处理。
4.3.5 性能调整
优化设备内存带宽利用率有两个目标:
- 对齐及合并内存访问,以减少带宽的浪费
- 足够的并发内存操作,以隐藏内存延迟
实现并发内存访问最大化是通过以下方式获得的:
- 增加每个线程中执行独立内存操作的数量
- 对核函数启动的执行配置进行实验,以充分体现每个SM的并行性
4.3.5.1 展开技术
考虑之前的readSegment示例。按如下方式 readSegmentUnroll.cu 修改readOffset核函数,使每个线程都执行4个独立的内存操作。因为每个加载过程都是独立的,所以你可以调用更多的并发内存访问。
__global__ void readOffsetUnroll4(float *A, float *B, float *C, const int n,
int offset)
{
unsigned int i = blockIdx.x * blockDim.x * 4 + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[i] = A[k] + B[k];
if (k + blockDim.x < n) {
C[i + blockDim.x] = A[k + blockDim.x] + B[k + blockDim.x];
}
if (k + 2 * blockDim.x < n) {
C[i + 2 * blockDim.x] = A[k + 2 * blockDim.x] + B[k + 2 * blockDim.x];
}
if (k + 3 * blockDim.x < n) {
C[i + 3 * blockDim.x] = A[k + 3 * blockDim.x] + B[k + 3 * blockDim.x];
}
}相对于原来无循环展开的readSegment示例,这些测试说明使用循环展开技术实现了3.04~3.17倍的加速。对于这样一个I/O密集型的核函数,充分说明内存访问并行有很高的优先级。但是,展开并不影响执行内存操作的数量(只影响并发执行的数量)。
# jstson 16M数据
$ ./readSegmentUnroll 0
readOffset <<< 32768, 512 >>> offset 0 elapsed 0.004569 sec
unroll2 <<< 16384, 512 >>> offset 0 elapsed 0.004854 sec
unroll4 <<< 8192, 512 >>> offset 0 elapsed 0.004776 sec
$ ./readSegmentUnroll 11
readOffset <<< 32768, 512 >>> offset 11 elapsed 0.004606 sec
unroll2 <<< 16384, 512 >>> offset 11 elapsed 0.004898 sec
unroll4 <<< 8192, 512 >>> offset 11 elapsed 0.004793 sec
$ ./readSegmentUnroll 128
readOffset <<< 32768, 512 >>> offset 128 elapsed 0.004581 sec
unroll2 <<< 16384, 512 >>> offset 128 elapsed 0.004845 sec
unroll4 <<< 8192, 512 >>> offset 128 elapsed 0.004778 sec4.3.5.2 增大并行性
为了充分体现并行性,你应该用一个核函数启动的网格和线程块大小进行试验,以找到该核函数最佳的执行配置。运行以下测试代码,使用对齐内存访问(偏移量=0)的块大小进行实验。注意,你可能需要使用1/3的命令行参数来指定数据大小,否则在一个网格中线程块将超出限制。
# jstson 16M数据
$ ./readSegmentUnroll 0 1024 22
readOffset <<< 4096, 1024 >>> offset 0 elapsed 0.001525 sec
unroll2 <<< 2048, 1024 >>> offset 0 elapsed 0.001818 sec
unroll4 <<< 1024, 1024 >>> offset 0 elapsed 0.001744 sec
$ ./readSegmentUnroll 0 512 22
readOffset <<< 8192, 512 >>> offset 0 elapsed 0.001179 sec
unroll2 <<< 4096, 512 >>> offset 0 elapsed 0.001614 sec
unroll4 <<< 2048, 512 >>> offset 0 elapsed 0.001573 sec
$ ./readSegmentUnroll 0 256 22
readOffset <<< 16384, 256 >>> offset 0 elapsed 0.001155 sec
unroll2 <<< 8192, 256 >>> offset 0 elapsed 0.001575 sec
unroll4 <<< 4096, 256 >>> offset 0 elapsed 0.001595 sec
$ ./readSegmentUnroll 0 128 22
readOffset <<< 32768, 128 >>> offset 0 elapsed 0.001138 sec
unroll2 <<< 16384, 128 >>> offset 0 elapsed 0.001568 sec
unroll4 <<< 8192, 128 >>> offset 0 elapsed 0.001569 sec对于展开核函数而言,最佳的线程块大小为每块有256个线程(对jetson而言并非如此),与之前测试代码中使用的默认的每块有512个线程相比,线程块的数量加倍了。尽管每块有128个线程对GPU来说有了更多的并行性,但其性能比每块有256个线程稍差。当非对齐访问被执行时,可以验证线程块大小对性能的影响。以下结果与对齐访问示例产生的结果类似,与每个线程块有128、256和512个线程的完成情况非常类似。这表明,无论访问是否是对齐的,每个SM中相同的硬件资源限制仍会影响核函数的性能。
影响设备内存操作性能的因素主要有两个:
- 有效利用设备DRAM和SM片上内存之间的字节移动:为了避免设备内存带宽的浪费,内存访问模式应是对齐和合并的
- 当前的并发内存操作数:可通过以下两点实现最大化当前存储器操作数。1)展开,每个线程产生更多的独立内存访问,2)修改核函数启动的执行配置来使每个SM有更多的并行性
4.4 核函数可达到的带宽
在分析核函数性能时,需要注意内存延迟,即完成一次独立内存请求的时间;内存带宽,即SM访问设备内存的速度,它以每单位时间内的字节数进行测量。在上一节中已经尝试使用两种方法来改进核函数的性能:
- 通过最大化并行执行线程束的数量来隐藏内存延迟,通过维持更多正在执行的内存访问来达到更好的总线利用率
- 通过适当的对齐和合并内存访问来最大化内存带宽效率
4.4.1 内存带宽
大多数核函数对内存带宽非常敏感,也就是说它们有内存带宽的限制。因此,在调整核函数时需要注意内存带宽的指标。全局内存中数据的安排方式,以及线程束访问该数据的方式对带宽有显著影响。一般有如下两种类型的带宽:
- 理论带宽
- 有效带宽
$$
有效带宽(GB/s)=\frac{读字节数+写字节数·10^{-9}}{运行时间}
$$
4.4.2 矩阵转置问题
矩阵转置是线性代数中一个基本问题。虽然是基本问题,但却在许多应用程序中被使用。矩阵的转置意味着每一列与相应的一行进行互换。图所示为一个简单的矩阵和它的转置。以下是基于主机实现的使用单精度浮点值的错位转置算法。假设矩阵存储在一个一维数组中。通过改变数组索引值来交换行和列的坐标,可以很容易得到转置矩阵。
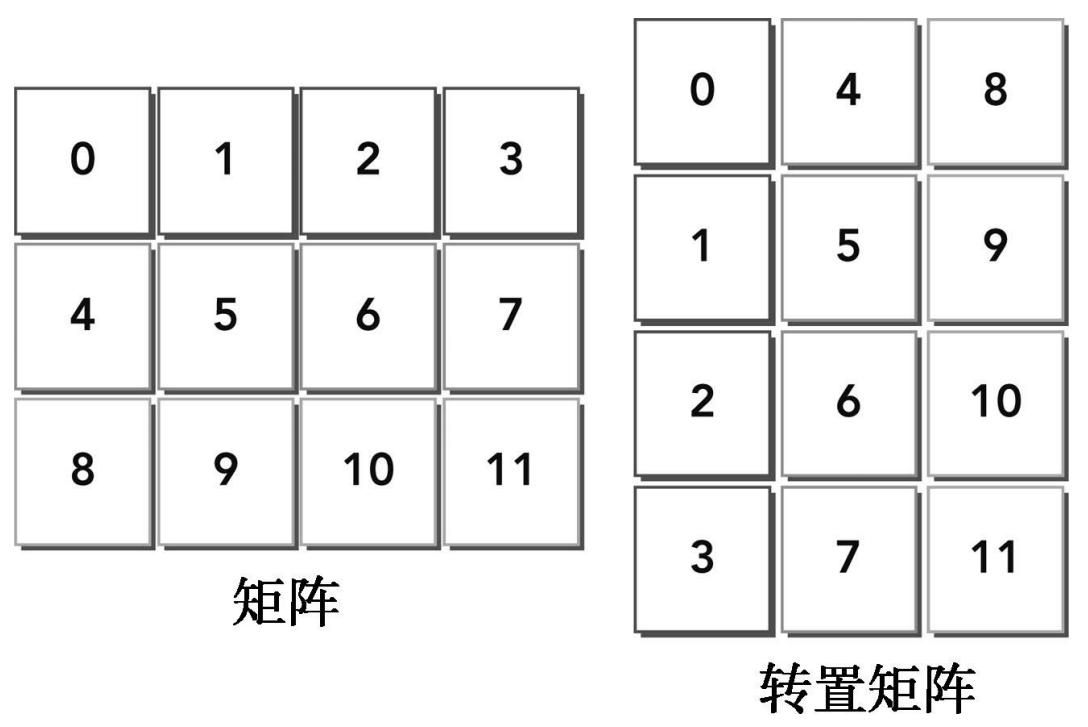
void transposeHost(float *out, float *in, const int nx, const int ny){
for (int iy = 0, iy < ny; iy++){
for (int ix = 0; ix < nx; ix++) {
out[ix*ny +iy] = in[iy*nx+ix];
}
}
}可以用一个一维数组执行转置操作,
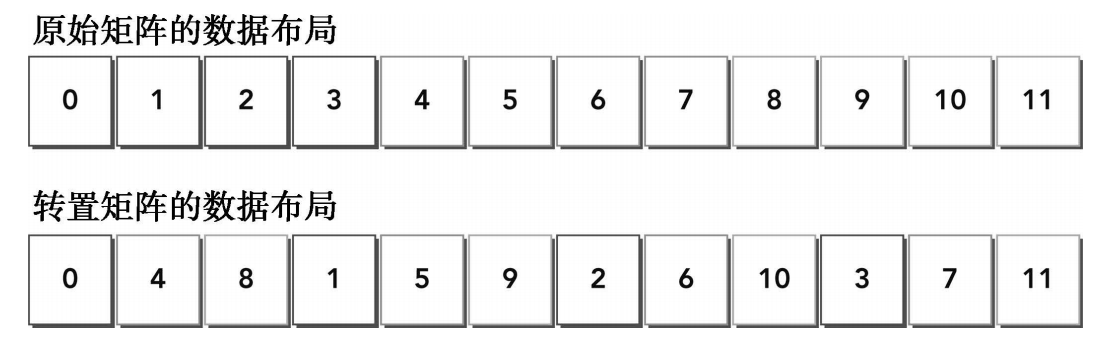
观察输入和输出布局,注意到:
- 读:通过原矩阵的行进行访问,结果为合并访问
- 写:通过转置矩阵的列进行访问,结果为交叉访问
交叉访问是使GPU性能变得最差的内存访问模式。但是,在矩阵转置操作中这是不可避免的。本节的剩余部分将侧重于使用两种转置核函数来提高带宽的利用率:一种是按行读取按列存储,另一种则是按列读取按行存储。如果禁用一级缓存加载,那么这两种实现的性能在理论上是相同的。但是,如果启用一级缓存,那么第二种实现的性能表现会更好。按列读取操作是不合并的(因此带宽将会浪费在未被请求的字节上),将这些额外的字节存入一级缓存意味着下一个读操作可能会在缓存上执行而不在全局内存上执行。因为写操作不在一级缓存中缓存,所以对按列执行写操作的例子而言,任何缓存都没有意义。
示例:transpose.cu
# jetson 最大约68GB/s
./transpose 0~7
./transpose starting transpose at device 0: Orin with matrix nx 4096 ny 4096 with kernel 0
CopyRow elapsed 0.003015 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 44.516048 GB
CopyCol elapsed 0.004467 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 30.046432 GB
NaiveRow elapsed 0.005998 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 22.377468 GB
NaiveCol elapsed 0.003134 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 42.826164 GB
Unroll4Row elapsed 0.006874 sec <<< grid (64, 256) block (16,16)>>> effective bandwidth 19.525179 GB
Unroll4Col elapsed 0.002745 sec <<< grid (64, 256) block (16,16)>>> effective bandwidth 48.896896 GB
DiagonalRow elapsed 0.005188 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 25.870861 GB
DiagonalCol elapsed 0.003703 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 36.246857 GB
禁用缓存:
CopyRow elapsed 0.003014 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 44.530132 GB
CopyCol elapsed 0.006341 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 21.166716 GB
NaiveRow elapsed 0.005928 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 22.641167 GB
NaiveCol elapsed 0.004570 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 29.369259 GB
Unroll4Row elapsed 0.006898 sec <<< grid (64, 256) block (16,16)>>> effective bandwidth 19.457693 GB
Unroll4Col elapsed 0.004197 sec <<< grid (64, 256) block (16,16)>>> effective bandwidth 31.980341 GB
DiagonalRow elapsed 0.005223 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 25.697264 GB
DiagonalCol elapsed 0.004300 sec <<< grid (256,256) block (16,16)>>> effective bandwidth 31.212572 GB| Function | Enable Cache | Band | Disable Cache | Band |
|---|---|---|---|---|
| CopyRow | 44.516048 GB | 65% | 44.530132 GB | 65% |
| CopyCol | 30.046432 GB | 44% | 21.166716 GB | 31% |
| NaiveRow | 22.377468 GB | 32% | 22.641167 GB | 33% |
| NaiveCol | 42.826164 GB | 63% | 29.369259 GB | 43% |
| Unroll4Row | 19.525179 GB | 27% | 19.457693 GB | 28% |
| Unroll4Col | 48.896896 GB | 72% | 31.980341 GB | 47% |
| DiagonalRow | 25.870861 GB | 38% | 25.697264 GB | 38% |
| DiagonalCol | 36.246857 GB | 53% | 31.212572 GB | 46% |
H800:
SXM 与 PCIe:最适合训练 LLM 的 GPU,如 GPT-4
H800详细配置
| Function | Enable Cache | Disable Cache |
|---|---|---|
| CopyRow | 1050.279785 GB | 991.109070 GB |
| CopyCol | 863.420166 GB | 714.403503 GB |
| NaiveRow | 657.651794 GB | 670.178528 GB |
| NaiveCol | 984.178223 GB | 902.163391 GB |
| Unroll4Row | 541.298035 GB | 622.732239 GB |
| Unroll4Col | 1012.499939 GB | 885.141418 GB |
| DiagonalRow | 686.524353 GB | 657.651794 GB |
| DiagonalCol | 932.036377 GB | 885.141418 GB |
4.4.2.1 为转置核函数设置性能的上限和下限
- CopyRow 通过加载和存储行来拷贝矩阵(上限)。这样将模拟执行相同数量的内存操作作为转置,但是只能使用合并访问
- CopyCol 通过加载和存储列来拷贝矩阵(下限)。这样将模拟执行相同数量的内存操作作为转置,但是只能使用交叉访问
4.4.2.2 朴素转置:读取行与读取列
- NaiveRow 基于行的朴素转置核函数是基于主机实现的。这种转置按行加载按列存储,合并读取交叉写入
- NaiveCol 通过互换读索引和写索引,就生成了基于列的朴素转置核函数,按列加载按行存储,交叉读取合并写入
结果表明,使用NaiveCol方法比NaiveRow方法性能表现得更好。如前面所述,导致这种性能提升的一个可能原因是在缓存中执行了交叉读取。即使通过某一方式读入一级缓存中的数据没有都被这次访问使用到,这些数据仍留在缓存中,在以后的访问过程中可能发生缓存命中。禁用缓存加载对交叉读取访问模式有显著影响。通过缓存交叉读取能够获得最高的加载吞吐量。在缓存读取的情况下,每个内存请求由一个128字节的缓存行来完成。按列读取数据,使得线程束里的每个内存请求都会重复执行32次,一旦数据预先存储到了一级缓存中,那么许多当前全局内存读取就会有良好的隐藏延迟并取得较高的一级缓存命中率。对于NaiveCol实现而言,由于合并写入,存储请求从未被重复执行,但是由于交叉读取,多次重复执行了加载请求。这证明了即使是较低的加载效率,一级缓存中的缓存加载也可以限制交叉加载对性能的负面影响。
4.4.2.3 展开转置:读取行与读取列
利用展开技术来提高转置内存带宽的利用率。展开的目的是为每个线程分配更独立的任务,从而最大化当前内存请求。
4.4.2.4 对角转置:读取行与读取列
略
4.4.2.5 使用瘦块来增加并行性
目前最佳的块大小为(8,32),尽管它与大小为(16,16)的块显示了相同的并行性,但这种性能的提升是由“瘦的”块(8,32)带来的。
4.5 使用统一内存的矩阵加法
使用统一内存将以下解决方案添加到矩阵加法的主函数中:
- 用托管内存分配来替换主机和设备内存分配,以消除重复指针
- 删除所有显式的内存副本
sumMatrixGPUManaged.cu 使用指向托管内存的指针来初始化主机上的两个输入矩阵,通过指向托管内存的指针调用矩阵加法核函数。因为核函数的启动与主机程序是异步的,并且内存块cudaMemcpy的调用不需要使用托管内存,所以在直接访问核函数输出之前,需要在主机端显式地同步。相比于之前未托管内存的矩阵加法程序,这里的代码因为使用了统一内存而明显被简化了。
sumMatrixGPUManual.cu,它使用相同的矩阵加法核函数但不使用托管内存。相反,它显式地将数据拷贝到设备中或将数据拷贝出设备。
影响性能差异的最大因素在于CPU数据的初始化时间——使用托管内存耗费的时间更长。矩阵最初是在GPU上被分配的,由于矩阵是用初始值填充的,所以首先会在CPU上引用。这就要求底层系统在初始化之前,将矩阵中的数据从设备传输到主机中,这是manual版的核函数中不执行的传输。
$ ./sumMatrixGPUManual 13
./sumMatrixGPUManual Starting using Device 0: Orin
Matrix size: nx 8192 ny 8192
initialization: 4.506949 sec
sumMatrix on host: 0.303027 sec
sumMatrix on gpu : 0.020959 sec <<<(256,256), (32,32)>>>
$ ./sumMatrixGPUManaged 13
./sumMatrixGPUManaged Starting using Device 0: Orin
Matrix size: nx 8192 ny 8192
initialization: 4.411932 sec
sumMatrix on host: 0.301940 sec
sumMatrix on gpu : 0.031380 sec <<<(256,256), (32,32)>>>CUDA 6.0中发布的统一内存是用来提高程序员的编程效率的。底层系统强调性能的一致性和正确性。结果表明,在CUDA应用中手动优化数据移动的性能比使用统一内存的性能要更优,可以肯定的是,NVIDIA公司未来计划推出的硬件和软件将支持统一内存的性能提升和可编程性。
4.6 总结
全局内存是最大的、延迟最高的、最常用的内存。对全局内存的请求可以由32个字节或128个字节的事务来完成。
两种提高带宽利用率的方法:
- 最大化当前并发内存访问的次数
- 最大化在总线上的全局内存和SM片上内存之间移动字节的利用率
为保持有足够多的正在执行的内存操作,可以使用展开技术在每个线程中创建更多的独立内存请求,或调整网格和线程块的执行配置来体现充分的SM并行性。
为了避免在设备内存和片上内存之间有未使用数据的移动,应该努力实现理想的访问模式:对齐和合并内存访问。
对齐内存访问相对容易,但有时合并访问比较有挑战性。一些算法本身就无法合并访问,或实现起来有一定的困难。
改进合并访问的重点在于线程束中的内存访问模式。另一方面,消除分区冲突的重点则在于所有活跃线程束的访问模式。对角坐标映射是一种通过调整块执行顺序来避免分区冲突的方法。
通过消除重复指针以及在主机和设备之间显式传输数据的需要,统一内存大大简化了CUDA编程。CUDA 6.0中统一内存的实现明显地保持了性能的一致性和优越性。未来硬件和软件的提升将会提高统一内存的性能。