GPU Note
缩略词
| 缩略词 | 解释 |
|---|---|
| TCC | Texture Cache per Channel |
| UTC | Unified Translation Cache |
| ATC | Address Translation Cache 地址转换缓存 |
| ATS | Address Translation Service |
| RC | Root complex |
| SE | Sahder Engine |
| SPI | Shader Processor Input |
| HWS | Hardware Scheduling |
| TOPS | Tera Operations Per Second 每秒钟万亿次操作 |
| FLOPS | floating-point operations per second 每秒所执行的浮点运算次数 |
| NPU | Neural Network Processing Unit |
| DPU | Deep-Learning Processing Unit |
| die | 裸芯片 |
| SVC | Supervisor Call |
| GMII | Gigabit Medium Independent Interface 千兆介质独立接口 |
| XGMII | 10 Gigabit Media Independent Interfac 10Gb介质独立接口 |
| CU | Compute Unit 计算单元 / Coding Unit 编码单元 |
| DCU | Deep-learning Computing Unit 深度计算处理器 |
| RLC | Runtime Low-Power Controller 运行时低功耗控制器 / Run List Controller 运行列表控制器 |
| SRM | Save and Restore Machine |
| GFX | Graphics |
| HSA | Heterogeneous System Architecture |
| AQL | Architected Queuing Language |
| TPU | Tensor Processing Unit 张量处理器 |
| ROCm | Radeon Open Computing platform |
| CUDA | Compute Unified Device Architecture 统一计算设备架构 |
| EOP | End of Pipe |
| EOS | End of Shader |
| HIP | Heterogeneous-Compute Interface for Portability |
| IB | Indirect Buffer |
| CP | COMMAND PROCESSOR |
| DRM | Direct Rendering Manager |
| CPC | Command Processor Compute |
| CPG | Command Processor Graphics |
| CPF | Command Processor Fetcher |
| HDP | Host Data Path 主机数据通路 |
| PM4 | Promo4Lib |
| ACE | Asynchronies Compute Engines |
| MEC | Micro-Engine Computing |
| IH | Interrupt Handler |
| UMD | User Mode Driver 用户模式驱动 |
| KMD | Kernel Mode Driver |
| KFD | Kernel Fusion Driver 内核融合驱动 / KFD: Kernel Driver For HSA HSA内核驱动 |
| UMA | Uniform Memory Access 统一内存架构 |
| GDS | Global Data Share |
| LDS | Local data share |
| VGPR | Vector General Purpose Register |
| SRB | Special Register Block |
| VM | Virtual Memory / Virtual Machine |
| RB | Ring Buffer |
| DS | Data Sharing |
| UTCL1 | Unified Translation Cache L1 |
| UMC | Unified Memory Controller |
| GRBM | Graphics Register Bus Manager 图形寄存器总线管理器 |
| DMA | Direct Memory Access |
| SDMA | System Direct Memory Access 系统直接存储器访问 |
| RDMA | Remote Direct Memory Access |
| SEV | Secure Encrypted Virtualization 安全虚拟化 |
| ECU | Engine Control Unit 引擎控制单元 |
| DC | Dispatch Controller |
| KIQ | kernel interface queue |
| KCQ | KMD Compute Queue |
| KGQ | KMD graphics Queue |
| HIQ | HSA Interface Queue |
| DIQ | Debug Interface Queue |
| SVM | share virtual memory |
| UTC | Unified Translation Cache |
| EA | Efficiency Arbiter |
| VMID | Virtual Memory Identifier |
| MQD | Memory Queue Descriptor |
| HQD | Hardware Queue Descriptor |
| SEM | Semaphore 信号量 |
| SPM | Stream Performance Monitor |
| BMC | Baseboard Management Controller 基板管理控制器 |
| HBM | High Bandwidth Memory |
| BLAS | Basic Linear Algebra Subprograms 基础线性代数子程序库 |
GPU基础
NVIDIA Turing 架构深度介绍
A卡和N卡的架构有什么区别?
Nvidia 硬件架构
纹理缓存
GPU Texture - Mipmap, Bilinear and Cache
TLB和ATS,ATC
RC(Root Complex)进行DMA地址转换是需要时间的,相较于不进行地址转换,显然进行DMA地址转换会增加DMA访问的时间。尤其是访问驻留内存转换表时,采用地址转换的方案会大大增加DMA访问的时间。当单次传输需要多次内存访问时,地址转换无疑会大大降低传输效率。
为了减小地址转换的以上不良影响,设计人员常常在需要进行地址转换的地方添加地址转换缓存(Address Translation Cache, ATC)。在CPU中,这种地址转换缓存通常是指转译后备缓冲区(Translation Look-aside Bufer, TLB);在IO地址转换中,我们常用ATC来跟CPU的TLB加以区分。TLB与ATC的区别:TLB一次只服务于CPU的单个线程,而ATC服务于PCIe设备的多个IO function,每个IO function都相当于一个独立的线程。
RC: 在PCI Express(PCIe)系统中,根复合体(root complex)设备将处理器和内存子系统连接到由一个或多个交换设备组成的PCI Express交换结构。
来自AMD:
There are various reasons for enabling System Cache address translation, including:
- Avoiding host device driver and letting accelerators work directly with addresses provided by the host application
- Limiting the impact of “memory leakage” or an incorrectly programmed endpoint
- Address space conversion (smaller endpoint address range to larger system virtual address space)
- Providing scatter/gather functionality
- Virtualization support
- The System Cache includes an ATC function with companion ATS to support virtual address handling.
管中窥”GPU ISA”
LDS指令格式: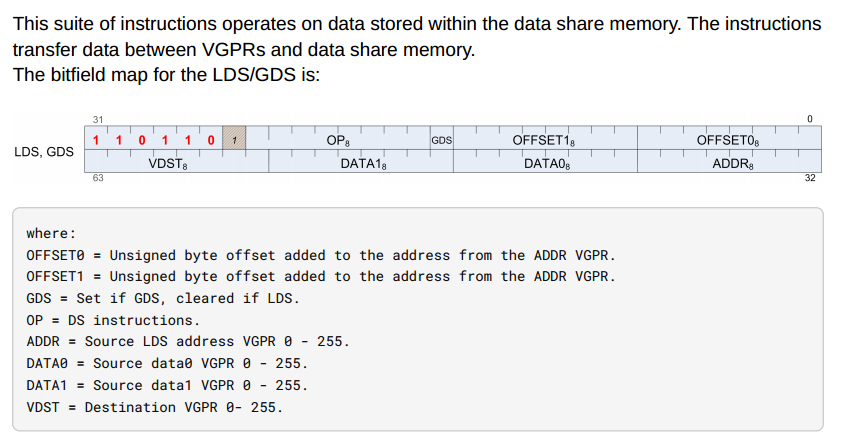
| Field Name | Bits | Format or Description |
|---|---|---|
| OFFSET0 | [7:0] | First address offset |
| OFFSET1 | [15:8] | Second address offset. For some opcodes this is concatenated with OFFSET0. |
| GDS | [16] | 1=GDS, 0=LDS operation. |
| OP | [24:17] | See Opcode table below. |
| ENCODING | [31:26] | Must be: 110110 |
| ADDR | [39:32] | VGPR which supplies the address. |
| DATA0 | [47:40] | First data VGPR. |
| DATA1 | [55:48] | Second data VGPR. |
| VDST | [63:56] | Destination VGPR when results returned to VGPRs. |
两个简单的DS opcode:
| OPCODE | Name | Description |
|---|---|---|
| 13 | DS_WRITE_B32 | MEM[ADDR] = DATA. // Write dword. 32bit |
| 54 | DS_READ_B32 | RETURN_DATA = MEM[ADDR]. // Dword read. |
HIP
#include <hip/hip_runtime.h>
extern "C"
__global__ void ds_read_b32(int *out) {
HIP_DYNAMIC_SHARED(int, sharedTmp);
// init the lds
sharedTmp[threadIdx.x] = threadIdx.x;
__syncthreads();
int ldsAddr = threadIdx.x * 4;
int result;
asm volatile(
"ds_read_b32 %0 ,%1\n"
"s_waitcnt lgkmcnt(0)"
: "=v"(result)
: "v"(ldsAddr)
:);
out[threadIdx.x] = result;
}这段代码是使用 AMD 的 HIP(Heterogeneous-Compute Interface for Portability)编写的一个 CUDA 核函数。HIP 是一个用于编写可移植 GPU 加速代码的工具,它允许开发者在不同的 GPU 架构上编写相似的代码,并且可以通过编译时选择目标架构进行优化。
asm volatile(...)这是一个内联汇编语句,允许在 CUDA/HIP 程序中直接嵌入 GPU 汇编指令。在这里,使用了 ds_read_b32 汇编指令来从动态共享内存中读取一个 32 位整数,并将结果存储在 result 中。
这段内联汇编代码是针对 AMD GPU 架构中的数据寄存器(DS - Data Share)指令 ds_read_b32 的调用。DS 指令结构解释:
OFFSET0和OFFSET1:用于指定地址的偏移量。GDS:用于指示是 GDS(Global Data Share)还是 LDS(Local Data Share)操作。在这里,GDS为 0,表示是一个 LDS(本地数据共享)操作。OP:操作码,指定 DS 指令的具体操作类型。在这里,未给出具体的操作码,因此在这段代码中的ds_read_b32指令将会执行读取操作。ENCODING:固定为 110110,用于识别 DS 指令。ADDR:VGPR 寄存器,用于提供地址。DATA0和DATA1:VGPR 寄存器,用于存储读取的数据。VDST:目的 VGPR 寄存器,用于存储结果。
内联汇编代码解释:
asm volatile(
"ds_read_b32 %0 ,%1\n"
"s_waitcnt lgkmcnt(0)"
: "=v"(result) // 输出操作数,将结果写入 result 变量
: "v"(ldsAddr) // 输入操作数,使用 ldsAddr 变量作为地址
:); // 没有使用到任何 clobbered 寄存器"ds_read_b32 %0 ,%1\n":这是内联汇编中的字符串指令,调用了 DS 指令ds_read_b32。其中%0和%1分别对应输出操作数和输入操作数的位置。在这里,%0对应输出结果result的位置,%1对应输入参数ldsAddr的位置。这条指令的作用是从ldsAddr指定的本地数据共享内存中读取一个 32 位整数,并将结果存储到result变量中。"s_waitcnt lgkmcnt(0)":这是一个 HIP 的函数调用,用于等待指令发出前面的所有访存请求完成。在这里,确保ds_read_b32指令执行完毕后再继续执行后续指令。: "=v"(result):这部分是输出操作数(output operands),通过=v指定了将结果存储到result变量中,v表示使用 VGPR。: "v"(ldsAddr):这部分是输入操作数(input operands),指定了使用ldsAddr变量作为输入地址,同样使用了 VGPR。::最后的:表示 clobbered 寄存器列表为空,即没有修改其他寄存器的需要。
综上所述,这段内联汇编代码通过 ds_read_b32 指令从本地数据共享内存中读取一个 32 位整数,并将结果存储到 result 变量中。然后使用 s_waitcnt lgkmcnt(0) 确保了前面的读取操作已经完成,然后程序继续执行。
汇编
这段代码是一个使用 AMD GPU 架构的 HIP 编写的内核函数 ds_read_b32 的汇编代码。让我们一行一行地解释并添加注释:
.text
.protected ds_read_b32 ; -- Begin function ds_read_b32
.globl ds_read_b32
.p2align 8
.type ds_read_b32,@function
ds_read_b32: ; @ds_read_b32.text: 这表示接下来的指令是代码段,包含程序的可执行指令。.protected ds_read_b32: 声明ds_read_b32函数为受保护的,表示其他文件可以使用这个函数。.globl ds_read_b32: 将ds_read_b32函数声明为全局可见,使其可以在其他文件中被调用。.p2align 8: 将下一个符号(symbol)对齐到 2^8 字节(即 256 字节)的边界。.type ds_read_b32,@function: 声明ds_read_b32是一个函数。
; %bb.0: ; %entry
s_load_dwordx2 s[0:1], s[4:5], 0x0
v_lshlrev_b32_e32 v1, 2, v0
v_add_u32_e32 v2, 0, v1
ds_write_b32 v2, v0
s_waitcnt lgkmcnt(0)
v_mov_b32_e32 v3, s1
v_add_co_u32_e32 v0, vcc, s0, v1
s_barrier
s_waitcnt lgkmcnt(0)
;;#ASMSTART
ds_read_b32 v2 ,v1
s_waitcnt lgkmcnt(0)
;;#ASMEND
v_addc_co_u32_e32 v1, vcc, 0, v3, vcc
global_store_dword v[0:1], v2, off
s_endpgm这里是核函数的主体部分。解释如下:
s_load_dwordx2 s[0:1], s[4:5], 0x0: 从内存中加载两个双字(32 位整数)到s[0:1]寄存器中。v_lshlrev_b32_e32 v1, 2, v0: 将寄存器v0中的值左移 2 位,并将结果存储到v1中。v_add_u32_e32 v2, 0, v1: 将寄存器v1的值与 0 相加,并将结果存储到v2中。ds_write_b32 v2, v0: 将寄存器v2的值写入数据段(data segment)中的v0地址。s_waitcnt lgkmcnt(0): 等待指令发出前面的所有访存请求完成。v_mov_b32_e32 v3, s1: 将寄存器s1的值移动到v3中。v_add_co_u32_e32 v0, vcc, s0, v1: 将s0和v1相加,进位存放在vcc中,结果存放在v0中。s_barrier: 同步所有线程,等待所有线程完成之前的任务。s_waitcnt lgkmcnt(0): 等待指令发出前面的所有访存请求完成。ds_read_b32 v2, v1: 从数据段读取v1地址处的数据到寄存器v2中。s_waitcnt lgkmcnt(0): 等待指令发出前面的所有访存请求完成。v_addc_co_u32_e32 v1, vcc, 0, v3, vcc: 将v3与 0 相加,进位存放在vcc中,结果存放在v1中。global_store_dword v[0:1], v2, off: 将v2中的值存储到全局内存中的v[0:1]地址偏移off处。s_endpgm: 结束程序。
.section .rodata,#alloc
.p2align 6
.amdhsa_kernel ds_read_b32
.amdhsa_group_segment_fixed_size 0
.amdhsa_private_segment_fixed_size 0
.amdhsa_kernarg_size 64
.amdhsa_user_sgpr_private_segment_buffer 1
.amdhsa_user_sgpr_dispatch_ptr 0
.amdhsa_user_sgpr_queue_ptr 0
.amdhsa_user_sgpr_kernarg_segment_ptr 1
.amdhsa_user_sgpr_dispatch_id 0
.amdhsa_user_sgpr_flat_scratch_init 0
.amdhsa_user_sgpr_private_segment_size 0
.amdhsa_system_sgpr_private_segment_wavefront_offset 0
.amdhsa_system_sgpr_workgroup_id_x 1
.amdhsa_system_sgpr_workgroup_id_y 0
.amdhsa_system_sgpr_workgroup_id_z 0
.amdhsa_system_sgpr_workgroup_info 0
.amdhsa_system_vgpr_workitem_id 0
.amdhsa_next_free_vgpr 4
.amdhsa_next_free_sgpr 6
.amdhsa_reserve_vcc 0
.amdhsa_reserve_flat_scratch 0
.amdhsa_reserve_xnack_mask 1
.amdhsa_float_round_mode_32 0
.amdhsa_float_round_mode_16_64 0
.amdhsa_float_denorm_mode_32 3
.amdhsa_float_denorm_mode_16_64 3
.amdhsa_dx10_clamp 1
.amdhsa_ieee_mode 1
.amdhsa_fp16_overflow 0
.amdhsa_exception_fp_ieee_invalid_op 0
.amdhsa_exception_fp_denorm_src 0
.amdhsa_exception_fp_ieee_div_zero 0
.amdhsa_exception_fp_ieee_overflow 0
.amd
hsa_exception_fp_ieee_underflow 0
.amdhsa_exception_fp_ieee_inexact 0
.amdhsa_exception_int_div_zero 0
.end_amdhsa_kernel这部分是 .rodata 段,用于存放只读数据和常量。这里包含了对 ds_read_b32 核函数的一些元数据和参数设置,例如:
amdhsa_kernel ds_read_b32: 声明ds_read_b32是一个 AMD HSA 核函数。- 设置了一系列 AMD HSA 核函数的参数,包括工作组段(group segment)大小、私有段(private segment)大小、Kernarg(kernel arguments)大小等。
- 针对寄存器的设置,包括下一个可用的 VGPR 和 SGPR 数量,保留的 VCC(向量寄存器控制)和 Flat Scratch 寄存器数量等。
- 设置了浮点数的舍入模式、IEEE 模式、异常处理等。
.Lfunc_end0:
.size ds_read_b32, .Lfunc_end0-ds_read_b32
; -- End function这是函数的结束标记,表示 ds_read_b32 函数的大小为 .Lfunc_end0 - ds_read_b32。
.section .AMDGPU.csdata
; Kernel info:
; codeLenInByte = 76
; NumSgprs: 8
; NumVgprs: 4
; ScratchSize: 0
; MemoryBound: 0
; FloatMode: 192
; IeeeMode: 1
; LDSByteSize: 0 bytes/workgroup (compile time only)
; SGPRBlocks: 0
; VGPRBlocks: 0
; NumSGPRsForWavesPerEU: 8
; NumVGPRsForWavesPerEU: 4
; Occupancy: 10
; WaveLimiterHint : 1
; COMPUTE_PGM_RSRC2:SCRATCH_EN: 0
; COMPUTE_PGM_RSRC2:USER_SGPR: 6
; COMPUTE_PGM_RSRC2:TRAP_HANDLER: 0
; COMPUTE_PGM_RSRC2:TGID_X_EN: 1
; COMPUTE_PGM_RSRC2:TGID_Y_EN: 0
; COMPUTE_PGM_RSRC2:TGID_Z_EN: 0
; COMPUTE_PGM_RSRC2:TIDIG_COMP_CNT: 0
.protected _ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE ; @_ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE
.type _ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE,@object
.section .rodata._ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE,#alloc
.weak _ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE
_ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE:
.zero 1
.size _ZN17__HIP_CoordinatesI15__HIP_ThreadIdxE1xE, 1这部分包含了 AMDGPU 的一些元数据,例如内核信息、寄存器使用情况、内存占用等信息。也包含了对一些 HIP 相关的符号和数据的定义。
总的来说,这段代码是一个 AMD GPU 架构下的 HIP 内核函数 ds_read_b32 的汇编代码,用于在 GPU 上执行一些数据操作,包括从内存加载数据、进行计算、存储数据等。
VGPR
“Vector General Purpose Register”(VGP 寄存器)是指向量处理器架构中的一种寄存器类型。向量处理器是一种专门设计用于高效处理向量(数组)数据的处理器。VGP 寄存器用于存储向量操作中的数据,它们与普通的整数或浮点寄存器不同,因为它们可以同时处理多个元素。在向量处理器架构中,VGP 寄存器通常有较大的宽度,以便同时处理多个数据元素。例如,在某些向量处理器中,一个 VGP 寄存器可能能够存储一组浮点数或整数,而不仅仅是单个浮点数或整数。使用 VGP 寄存器,程序员可以编写针对整个向量的操作,而不是逐个元素地处理。这种向量化的操作可以显著提高处理器的性能,特别是在处理大量数据时,因为它们允许并行处理多个元素。
AMD GPU LLVM
HSAKMT
HSAKMT(HSA Kernel Mode Thunk)是一种用于支持异构系统架构(HSA)的软件层。在异构计算中,多种处理器(如CPU、GPU、DSP等)共同工作,处理各种不同类型的计算任务。为了优化这些不同处理器之间的数据交换和处理效率,HSA旨在提供统一的内存视图,即统一内存寻址(Unified Memory Addressing,UMA),这是通过HSAKMT等机制实现的。
统一内存寻址是一种使CPU和GPU(以及其他可能的处理器)可以共享相同物理内存的技术。在传统的系统中,CPU和GPU通常拥有独立的内存空间,数据必须在这些内存空间之间显式复制,这会导致性能下降和编程复杂性增加。通过实现统一内存寻址,HSA架构允许所有的处理器看到一个连续且一致的内存地址空间,从而简化了数据共享和通信。处理器可以直接访问共享内存中的数据,无需进行数据复制,这显著提高了效率和响应速度。
HSAKMT的角色
HSAKMT是Linux下的一种内核模式驱动程序,提供了一套接口(thunks),允许用户空间应用程序与HSA兼容硬件进行交互。这些接口支持包括但不限于内存管理、队列管理、信号量和中断管理等功能。在内存管理方面,HSAKMT处理以下关键功能:
- 内存分配和释放: 管理统一内存的分配和释放,确保不同处理器可以高效访问。
- 内存映射: 允许不同的处理器单元映射相同的物理内存地址,实现真正的内存共享。
- 地址转换: 在需要时提供地址转换服务,以支持老旧设备或特殊情况下的兼容性。
总体而言,HSAKMT在实现HSA架构的统一内存寻址中扮演着核心角色,通过提供底层的内存管理和控制,使得异构计算设备能够更加高效地协同工作。这种技术在需要大量数据处理和高并行计算能力的应用场景(如大数据分析、机器学习和科学计算等)中尤为重要。
什么是Wavefront
现代渲染引擎开发-GPU架构 - 知乎 (zhihu.com)
对应NVIDIA是warp,即线程束
Barrier in GPU
在GPU(图形处理单元)中,”barrier”(屏障)通常指的是内存屏障(memory barrier)或同步屏障(synchronization barrier)。
- 内存屏障(Memory Barrier):GPU中的内存屏障是用来确保对内存的访问操作的顺序性和可见性。GPU中的线程通常是并行执行的,可能会导致一些线程在其他线程之前完成了对内存的写入操作。内存屏障的作用是确保这些写入操作按照程序员指定的顺序被其他线程可见,从而避免数据的不一致性。
- 同步屏障(Synchronization Barrier):这种屏障用于确保在执行到该屏障之前的指令已经全部执行完成,然后才能继续执行之后的指令。这对于一些需要依赖先前指令结果的指令序列是非常重要的,确保程序的正确性和可靠性。
在GPU编程中,程序员可能需要显式地使用这些屏障来控制线程的执行顺序和访问内存的可见性,以避免数据竞争和其他并发问题。
Fence
GPU中的“fence”是一种同步机制,用来确保在不同的GPU命令或不同的处理器(例如CPU和GPU)之间维持一定的执行顺序。在图形和计算应用程序中,正确的执行顺序是非常重要的,特别是在资源被多个任务共享时。
Fence的功能:
- 同步命令队列: 在多个GPU命令队列中使用时,fence可以确保一个队列中的命令在另一个队列的命令开始前完成。例如,在渲染图形前,确保所有的纹理加载完成。
- CPU与GPU同步: 确保CPU端的数据操作完成后,GPU才开始执行相关的图形或计算任务。或者反过来,确保GPU任务完成后,CPU才处理GPU的输出数据。
- 资源管理: 在使用共享资源,如内存、缓冲区或纹理时,fence帮助管理访问权限,防止数据冲突和损坏。
工作原理:
- 当GPU或CPU达到执行过程中的某个特定点(例如,提交一个重要的渲染命令后)时,它会插入一个fence。
- 这个fence将会设置一个标记或标志,表明到达了某个执行阶段。
- 其他任务(无论是在GPU还是CPU上)在继续执行前,必须等待这个fence标志被触发,表明之前的任务已经完成了必需的处理。
应用示例:在一个典型的游戏或高性能计算应用中,可能需要加载大量的纹理数据到GPU。在这些纹理被加载之前开始渲染过程,将会导致错误或未完成的渲染输出。通过在纹理加载命令后设置一个fence,然后在渲染命令前检查这个fence,开发者可以确保渲染过程只在所有纹理加载完成后开始。
总的来说,fence是维护高效、可靠和正确的数据处理与计算顺序的关键工具,在高性能计算和复杂图形处理中尤其重要。
什么是chiplet和die
多Die封装:Chiplet小芯片的研究报告_Tofino (sohu.com)
被寄予厚望的Chiplet技术 (baidu.com)
GPU架构/集群
GPU集群网络、集群规模、集群算力 - 知乎 (zhihu.com)
NVIDIA GPU 架构梳理 - 知乎 (zhihu.com)
NVLink版与PCIe版GPU,究竟有什么区别? (qq.com)
简单说说算力网络:什么是InfiniBand? (qq.com)
简单说说算力网络:DGX A100如何组集群? (qq.com)
简单说说算力网络:集群互联,选RoCE还是InfiniBand? (qq.com)
简单说说算力网络:128台H100如何组集群? (qq.com)
如何估算大模型训练所需算力? (qq.com)
简单说说算力网络:英伟达最新GPU互联架构 (qq.com)
35页PPT,了解InfiniBand和RoCE (qq.com)
RDMA
深入浅出全面解析RDMA技术 - 知乎 (zhihu.com)
RDMA技术详解(一):RDMA概述 - 知乎 (zhihu.com)
(24 封私信 / 80 条消息) 在各互联网公司中,有将 RDMA 技术用于生产环境的实例吗? - 知乎 (zhihu.com)
从DPU开始到RDMA到CUDA - 知乎 (zhihu.com)
SDMA
SDMA(Stream Direct Memory Access)和 RDMA(Remote Direct Memory Access)是两种数据传输技术,它们在功能和应用领域有所不同。
SDMA通常指在一个设备内部,例如GPU或特定的硬件加速器中,用于管理内存与内存之间或内存与设备之间的数据传输的技术。SDMA使得数据传输可以绕过主处理器(CPU),从而减少延迟和CPU的负载,提高整体系统效率。特点和应用:
- 高效数据管理: SDMA允许设备直接从内存中读写数据,无需通过CPU进行中间处理。
- 多用途: 常见于GPU、DSP(数字信号处理器)等,用于处理大量数据流,如视频处理、图像渲染等。
- 改善性能: 减少处理器的负载,使设备能更快地处理数据。
RDMA是一种网络技术,允许网络中的一台计算机直接访问另一台计算机的内存,无需通过操作系统处理数据,从而极大地提高数据传输的速度和效率。这种方式特别适合高性能计算和大规模数据中心。特点和应用:
- 低延迟、高吞吐量: RDMA减少了数据传输过程中的延迟,提高了网络传输的吞吐量。
- CPU卸载: 数据传输过程中不占用CPU资源,允许CPU处理其他更为复杂的任务。
- 应用广泛: 在数据中心、云计算、文件存储服务以及高性能计算中有广泛应用,如实现高效的大规模集群通信。
总结来说,SDMA关注的是设备内部或设备与内存之间的高效数据流动,而RDMA关注的是网络中不同计算机之间的高效数据交换。两者都旨在提高数据处理速度,减少CPU负载,但应用的具体环境和目标不同。
NVLink 和 RDMA 都是高速数据传输技术,但它们的设计目标和应用领域有所不同。然而,它们可以互补使用,以优化数据中心、高性能计算或深度学习应用的性能。
NVLink
NVLink 是由 NVIDIA 开发的一种高带宽、低延迟的数据传输接口,主要用于连接 GPU 与 GPU 之间,或 GPU 与 CPU 之间。NVLink 的设计目标是为了超越传统的PCI Express(PCIe)总线的带宽限制,提供更快的数据传输速率,从而加速数据密集型应用,尤其是在需要多个 GPU 协同工作的场景中。特点:
- 高带宽: NVLink 提供比 PCIe 更高的传输带宽,大大提升了 GPU 间的数据交换速度。
- 低延迟: 直接连接 GPU 间或 GPU 与 CPU 之间的接口减少了通信延迟。
- 多连接配置: 支持将多个 GPU 以链式或网格形式互连,提高并行处理能力。
NVLink 与 RDMA 的联系:虽然 NVLink 主要用于连接 GPU(或 GPU 与 CPU),而 RDMA 用于优化网络中的计算机间通信,但两者可以结合使用,以提高整体系统的数据处理能力和效率:
- 数据中心和云环境: 在包含多个 GPU 节点的数据中心,NVLink 可用于加速节点内部的 GPU 通信,而 RDMA 可以用来优化节点之间的通信。
- 高性能计算: 在需要大量数据交换的高性能计算应用中,NVLink 提升同一节点内多 GPU 之间的通信速度,RDMA 则加快不同计算节点间的数据交换。
通过这种方式,两种技术互补,共同提高了处理速度和效率,特别是在深度学习、科学计算等要求高并行处理能力的场景中。这种组合允许大规模系统中的快速数据传输,同时优化资源使用,实现高效的数据处理和计算性能。
RoCE(RDMA over Converged Ethernet)
RoCE 是在传统以太网基础上实现的 RDMA 技术。它允许在以太网环境中实施 RDMA,这意味着可以在不需要专门硬件(如 InfiniBand)的情况下,利用现有的以太网基础设施实现 RDMA 的优势。特点:
- 以太网兼容: 使用现有的以太网技术,降低实施 RDMA 的门槛和成本。
- 版本多样性: 包括 RoCE v1(不依赖于特定的以太网技术)和 RoCE v2(支持路由,可以在多个网络间传输数据)。
- 灵活性和普及性: 由于基于广泛使用的以太网,RoCE 在企业和数据中心中更易于部署和扩展。
RDMA 和 RoCE 的联系与区别:
RoCE(RDMA over Converged Ethernet)和 RDMA(Remote Direct Memory Access)之间存在直接的联系,但也有一些区别。RDMA 是一种通用的技术概念,而 RoCE 是这种技术的一种具体实现方式。
- 联系: RoCE 是 RDMA 的一种实现,提供了在以太网上实施 RDMA 的方法。它保留了 RDMA 的所有优势,如低延迟、高吞吐量和低 CPU 利用率。
- 区别: RDMA 是一种更广泛的技术概念,可以通过多种传输方式实现,包括 InfiniBand、iWARP(Internet Wide Area RDMA Protocol)以及 RoCE。RoCE 特别是指在以太网上实现的 RDMA。
总之,RoCE 使得在传统以太网基础上实施 RDMA 成为可能,这样不仅可以利用现有的网络基础设施,还能享受 RDMA 技术带来的低延迟和高效率优势。这种技术特别适合那些希望在不更换现有网络硬件的情况下,提升网络性能的应用场景。
开发
什么是内存地址对齐
DW aligned,最低两位为0,四字节对齐。QW aligned,最低三位为0,八字节(四字)对齐。为什么需要这样的对齐:
- 硬件效率:很多计算机架构设计中,CPU从内存中读取数据最为高效的方式是从某个固定边界开始。如果数据存储在对齐的地址上,CPU可以在一个或少数几个内存访问周期内读取完整的数据块,否则可能需要多次访问,增加延迟。
- 防止硬件异常:在某些硬件平台上,如x86和x64架构,如果尝试从非对齐的地址加载或存储Dword数据,可能导致硬件异常,如对齐检查异常(Alignment Check exception)。这种异常处理会降低程序的执行效率。
- 简化内存管理:对齐内存地址简化了内存的管理。系统不必考虑跨越多个内存页或缓存行来处理单个数据单位,降低了处理的复杂性和潜在的性能问题。
因此,对于32位数据(Dword),最低两位为0的地址对齐要求确保了数据处理的效率和程序的稳定运行。在编程和系统设计时,通常会采用专门的内存分配函数来确保所分配的内存满足对齐要求,例如在C语言中使用aligned_alloc函数或在其他高级语言中使用类似机制。
类静态定义
#include <iostream>
using namespace std;
struct test {
int a;
int b;
static int c;
};
/* should declare the static first */
int test::c = 3;
int main() {
printf("sizeof(test) = %d\n", sizeof(struct test));
struct test t1;
t1.a = 1;
t1.b = 2;
printf("sizeof(t) = %d\n", sizeof(t1));
printf("t1.c = %d\n", t1.c);
struct test t2;
printf("t2.c = %d\n", t2.c);
t2.c = 4;
printf("t1.c = %d\n", t1.c);
// undefined reference to `test::c'
// t.c = 3;
return 0;
}
sizeof(test) = 8
sizeof(t) = 8
t1.c = 3
t2.c = 3
t1.c = 4驱动
AMD GPU是怎么创建queue的
代码
// ----------------------------------------------------------------------------------------------------------------------------------
// kfdtest
// ----------------------------------------------------------------------------------------------------------------------------------
class BaseQueue
--> HSAKMT_STATUS Create(unsigned int NodeId, unsigned int size = DEFAULT_QUEUE_SIZE, HSAuint64 *pointers = NULL);
--> memset(&m_Resources, 0, sizeof(m_Resources));
--> hsaKmtCreateQueue(NodeId, type, DEFAULT_QUEUE_PERCENTAGE, DEFAULT_PRIORITY, m_QueueBuf->As<unsigned int*>(), m_QueueBuf->Size(), NULL, &m_Resources);
// ----------------------------------------------------------------------------------------------------------------------------------
// Thunk
// ----------------------------------------------------------------------------------------------------------------------------------
--> struct kfd_ioctl_create_queue_args args = {0};
--> handle_concrete_asic(q, &args, NodeId, Event, QueueResource->ErrorReason);
--> args.read_pointer_address = QueueResource->QueueRptrValue;
args.write_pointer_address = QueueResource->QueueWptrValue;
args.ring_base_address = (uintptr_t)QueueAddress;
args.ring_size = QueueSizeInBytes;
args.queue_percentage = QueuePercentage;
args.queue_priority = priority_map[Priority+3];
--> err = kmtIoctl(kfd_fd, AMDKFD_IOC_CREATE_QUEUE, &args);
// ----------------------------------------------------------------------------------------------------------------------------------
// Driver
// ----------------------------------------------------------------------------------------------------------------------------------
--> static int kfd_ioctl_create_queue(struct file *filep, struct kfd_process *p, void *data)
--> set_queue_properties_from_user(&q_properties, args);
--> q_properties->is_interop = false;
q_properties->is_gws = false;
q_properties->queue_percent = args->queue_percentage;
q_properties->priority = args->queue_priority;
q_properties->queue_address = args->ring_base_address;
q_properties->queue_size = args->ring_size;
q_properties->read_ptr = (uint32_t *) args->read_pointer_address;
q_properties->write_ptr = (uint32_t *) args->write_pointer_address;
q_properties->eop_ring_buffer_address = args->eop_buffer_address;
q_properties->eop_ring_buffer_size = args->eop_buffer_size;
q_properties->ctx_save_restore_area_address = args->ctx_save_restore_address;
q_properties->ctx_save_restore_area_size = args->ctx_save_restore_size;
q_properties->ctl_stack_size = args->ctl_stack_size;
//...
--> kfd_process_device_data_by_id()
--> kfd_bind_process_to_device()
--> pqm_create_queue(&p->pqm, dev, filep, &q_properties, &queue_id, NULL, NULL, NULL, &doorbell_offset_in_process);
--> struct kfd_process_device *pdd = kfd_get_process_device_data()
// PM4Queue.hpp: Type is HSA_QUEUE_COMPUTE --> KFD_IOC_QUEUE_TYPE_COMPUTE --> KFD_QUEUE_TYPE_COMPUTE
// SDMAQueue.hpp: Type is HSA_QUEUE_SDMA --> KFD_IOC_QUEUE_TYPE_SDMA --> KFD_QUEUE_TYPE_SDMA
--> init_user_queue(pqm, dev, &q, properties, f, *qid);
--> kfd_process_drain_interrupts(pdd);
--> retval = dev->dqm->ops.create_queue(dev->dqm, q, &pdd->qpd, q_data, restore_mqd, restore_ctl_stack);
// dqm->ops.create_queue = create_queue_cpsch;
--> create_queue_cpsch()
--> allocate_doorbell()
--> mqd_mgr->init_mqd(mqd_mgr, &q->mqd, q->mqd_mem_obj, &q->gart_mqd_addr, &q->properties);
--> list_add(&q->list, &qpd->queues_list);
--> increment_queue_count(dqm, qpd, q);
--> execute_queues_cpsch(dqm, KFD_UNMAP_QUEUES_FILTER_DYNAMIC_QUEUES, 0, USE_DEFAULT_GRACE_PERIOD);
--> retval = unmap_queues_cpsch(dqm, filter, filter_param, grace_period, false);
--> retval = pm_send_unmap_queue(&dqm->packet_mgr, filter, filter_param, reset);
--> pm_send_query_status(&dqm->packet_mgr, dqm->fence_gpu_addr, KFD_FENCE_COMPLETED);
--> retval = amdkfd_fence_wait_timeout(dqm->fence_addr, KFD_FENCE_COMPLETED, queue_preemption_timeout_ms);
--> pm_release_ib(&dqm->packet_mgr);
--> map_queues_cpsch(dqm);
--> pm_send_runlist(&dqm->packet_mgr, &dqm->queues);
--> retval = pm_create_runlist_ib(pm, dqm_queues, &rl_gpu_ib_addr, &rl_ib_size);
--> retval = kq_acquire_packet_buffer(pm->priv_queue, ket_size_dwords, &rl_buffer);
--> retval = pm->pmf->runlist(pm, rl_buffer, rl_gpu_ib_addr, rl_ib_size / sizeof(uint32_t), false);
--> pm_runlist_v9()
--> kq_submit_packet(pm->priv_queue);
--> write_kernel_doorbell()
--> writel(value, db);
--> __io_bw();
__raw_writel((u32 __force)__cpu_to_le32(value), addr);
__io_aw();
--> dqm->active_runlist = true;
--> deallocate_doorbell(qpd, q);
/** Ioctl table */
static const struct amdkfd_ioctl_desc amdkfd_ioctls[] = {
//...
AMDKFD_IOCTL_DEF(AMDKFD_IOC_CREATE_QUEUE,
kfd_ioctl_create_queue, 0),
//...
}
amdgpu_amdkfd_device_init()
--> adev->kfd.init_complete = kgd2kfd_device_init(adev->kfd.dev, adev_to_drm(adev), &gpu_resources);
--> kfd->dqm = device_queue_manager_init(kfd);
--> case KFD_SCHED_POLICY_HWS_NO_OVERSUBSCRIPTION:
/* initialize dqm for cp scheduling */
dqm->ops.create_queue = create_queue_cpsch;
dqm->ops.initialize = initialize_cpsch;
dqm->ops.start = start_cpsch;
dqm->ops.stop = stop_cpsch;
dqm->ops.pre_reset = pre_reset;
dqm->ops.destroy_queue = destroy_queue_cpsch;
dqm->ops.update_queue = update_queue;
dqm->ops.register_process = register_process;
dqm->ops.unregister_process = unregister_process;
dqm->ops.uninitialize = uninitialize;
dqm->ops.create_kernel_queue = create_kernel_queue_cpsch;
dqm->ops.destroy_kernel_queue = destroy_kernel_queue_cpsch;
dqm->ops.set_cache_memory_policy = set_cache_memory_policy;
dqm->ops.process_termination = process_termination_cpsch;
dqm->ops.evict_process_queues = evict_process_queues_cpsch;
dqm->ops.restore_process_queues = restore_process_queues_cpsch;
dqm->ops.get_wave_state = get_wave_state;
dqm->ops.reset_queues = reset_queues_cpsch;
dqm->ops.get_queue_checkpoint_info = get_queue_checkpoint_info;
dqm->ops.checkpoint_mqd = checkpoint_mqd;
break;
--> kfd_resume()
--> kfd->dqm->ops.start(kfd->dqm);
--> retval = pm_init(&dqm->packet_mgr, dqm);
--> pm->priv_queue = kernel_queue_init(dqm->dev, KFD_QUEUE_TYPE_HIQ);
--> kq_initialize(kq, dev, type, KFD_KERNEL_QUEUE_SIZE)
--> kq->mqd_mgr->init_mqd(kq->mqd_mgr, &kq->queue->mqd,
kq->queue->mqd_mem_obj,
&kq->queue->gart_mqd_addr,
&kq->queue->properties);
--> set_sched_resources(dqm)
--> return pm_send_set_resources(&dqm->packet_mgr, &res);
--> retval = pm->pmf->set_resources(pm, buffer, res);
--> pm_set_resources_v9()
static int pm_map_process_v9(struct packet_manager *pm,
uint32_t *buffer, struct qcm_process_device *qpd)
{
struct pm4_mes_map_process *packet;
uint64_t vm_page_table_base_addr = qpd->page_table_base;
struct kfd_dev *kfd = pm->dqm->dev;
struct kfd_process_device *pdd =
container_of(qpd, struct kfd_process_device, qpd);
packet = (struct pm4_mes_map_process *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_map_process));
packet->header.u32All = pm_build_pm4_header(IT_MAP_PROCESS,
sizeof(struct pm4_mes_map_process));
packet->bitfields2.diq_enable = (qpd->is_debug) ? 1 : 0;
packet->bitfields2.process_quantum = 10;
packet->bitfields2.pasid = qpd->pqm->process->pasid;
packet->bitfields14.gds_size = qpd->gds_size & 0x3F;
packet->bitfields14.gds_size_hi = (qpd->gds_size >> 6) & 0xF;
packet->bitfields14.num_gws = (qpd->mapped_gws_queue) ? qpd->num_gws : 0;
packet->bitfields14.num_oac = qpd->num_oac;
packet->bitfields14.sdma_enable = 1;
packet->bitfields14.num_queues = (qpd->is_debug) ? 0 : qpd->queue_count;
if (kfd->dqm->trap_debug_vmid && pdd->process->debug_trap_enabled &&
pdd->process->runtime_info.runtime_state == DEBUG_RUNTIME_STATE_ENABLED) {
packet->bitfields2.debug_vmid = kfd->dqm->trap_debug_vmid;
packet->bitfields2.new_debug = 1;
}
packet->sh_mem_config = qpd->sh_mem_config;
packet->sh_mem_bases = qpd->sh_mem_bases;
if (qpd->tba_addr) {
packet->sq_shader_tba_lo = lower_32_bits(qpd->tba_addr >> 8);
/* On GFX9, unlike GFX10, bit TRAP_EN of SQ_SHADER_TBA_HI is
* not defined, so setting it won't do any harm.
*/
packet->sq_shader_tba_hi = upper_32_bits(qpd->tba_addr >> 8)
| 1 << SQ_SHADER_TBA_HI__TRAP_EN__SHIFT;
packet->sq_shader_tma_lo = lower_32_bits(qpd->tma_addr >> 8);
packet->sq_shader_tma_hi = upper_32_bits(qpd->tma_addr >> 8);
}
packet->gds_addr_lo = lower_32_bits(qpd->gds_context_area);
packet->gds_addr_hi = upper_32_bits(qpd->gds_context_area);
packet->vm_context_page_table_base_addr_lo32 =
lower_32_bits(vm_page_table_base_addr);
packet->vm_context_page_table_base_addr_hi32 =
upper_32_bits(vm_page_table_base_addr);
return 0;
}
static int pm_runlist_v9(struct packet_manager *pm, uint32_t *buffer,
uint64_t ib, size_t ib_size_in_dwords, bool chain)
{
struct pm4_mes_runlist *packet;
int concurrent_proc_cnt = 0;
struct kfd_dev *kfd = pm->dqm->dev;
/* Determine the number of processes to map together to HW:
* it can not exceed the number of VMIDs available to the
* scheduler, and it is determined by the smaller of the number
* of processes in the runlist and kfd module parameter
* hws_max_conc_proc.
* Note: the arbitration between the number of VMIDs and
* hws_max_conc_proc has been done in
* kgd2kfd_device_init().
*/
concurrent_proc_cnt = min(pm->dqm->processes_count,
kfd->max_proc_per_quantum);
packet = (struct pm4_mes_runlist *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_runlist));
packet->header.u32All = pm_build_pm4_header(IT_RUN_LIST,
sizeof(struct pm4_mes_runlist));
packet->bitfields4.ib_size = ib_size_in_dwords;
packet->bitfields4.chain = chain ? 1 : 0;
packet->bitfields4.offload_polling = 0;
packet->bitfields4.chained_runlist_idle_disable = chain ? 1 : 0;
packet->bitfields4.valid = 1;
packet->bitfields4.process_cnt = concurrent_proc_cnt;
packet->ordinal2 = lower_32_bits(ib);
packet->ib_base_hi = upper_32_bits(ib);
return 0;
}
static int pm_set_resources_v9(struct packet_manager *pm, uint32_t *buffer,
struct scheduling_resources *res)
{
struct pm4_mes_set_resources *packet;
packet = (struct pm4_mes_set_resources *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_set_resources));
packet->header.u32All = pm_build_pm4_header(IT_SET_RESOURCES,
sizeof(struct pm4_mes_set_resources));
packet->bitfields2.queue_type =
queue_type__mes_set_resources__hsa_interface_queue_hiq;
packet->bitfields2.vmid_mask = res->vmid_mask;
packet->bitfields2.unmap_latency = KFD_UNMAP_LATENCY_MS / 100;
packet->bitfields7.oac_mask = res->oac_mask;
packet->bitfields8.gds_heap_base = res->gds_heap_base;
packet->bitfields8.gds_heap_size = res->gds_heap_size;
packet->gws_mask_lo = lower_32_bits(res->gws_mask);
packet->gws_mask_hi = upper_32_bits(res->gws_mask);
packet->queue_mask_lo = lower_32_bits(res->queue_mask);
packet->queue_mask_hi = upper_32_bits(res->queue_mask);
return 0;
}
static int pm_map_queues_v9(struct packet_manager *pm, uint32_t *buffer,
struct queue *q, bool is_static)
{
struct pm4_mes_map_queues *packet;
bool use_static = is_static;
packet = (struct pm4_mes_map_queues *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_map_queues));
packet->header.u32All = pm_build_pm4_header(IT_MAP_QUEUES,
sizeof(struct pm4_mes_map_queues));
packet->bitfields2.num_queues = 1;
packet->bitfields2.queue_sel =
queue_sel__mes_map_queues__map_to_hws_determined_queue_slots_vi;
packet->bitfields2.engine_sel =
engine_sel__mes_map_queues__compute_vi;
packet->bitfields2.gws_control_queue = q->gws ? 1 : 0;
packet->bitfields2.extended_engine_sel =
extended_engine_sel__mes_map_queues__legacy_engine_sel;
packet->bitfields2.queue_type =
queue_type__mes_map_queues__normal_compute_vi;
switch (q->properties.type) {
case KFD_QUEUE_TYPE_COMPUTE:
if (use_static)
packet->bitfields2.queue_type =
queue_type__mes_map_queues__normal_latency_static_queue_vi;
break;
case KFD_QUEUE_TYPE_DIQ:
packet->bitfields2.queue_type =
queue_type__mes_map_queues__debug_interface_queue_vi;
break;
case KFD_QUEUE_TYPE_SDMA:
case KFD_QUEUE_TYPE_SDMA_XGMI:
use_static = false; /* no static queues under SDMA */
if (q->properties.sdma_engine_id < 2 && !pm_use_ext_eng(q->device))
packet->bitfields2.engine_sel = q->properties.sdma_engine_id +
engine_sel__mes_map_queues__sdma0_vi;
else {
packet->bitfields2.extended_engine_sel =
extended_engine_sel__mes_map_queues__sdma0_to_7_sel;
packet->bitfields2.engine_sel = q->properties.sdma_engine_id;
}
break;
default:
WARN(1, "queue type %d", q->properties.type);
return -EINVAL;
}
packet->bitfields3.doorbell_offset =
q->properties.doorbell_off;
packet->mqd_addr_lo =
lower_32_bits(q->gart_mqd_addr);
packet->mqd_addr_hi =
upper_32_bits(q->gart_mqd_addr);
packet->wptr_addr_lo =
lower_32_bits((uint64_t)q->properties.write_ptr);
packet->wptr_addr_hi =
upper_32_bits((uint64_t)q->properties.write_ptr);
return 0;
}
static int pm_unmap_queues_v9(struct packet_manager *pm, uint32_t *buffer,
enum kfd_unmap_queues_filter filter,
uint32_t filter_param, bool reset)
{
struct pm4_mes_unmap_queues *packet;
packet = (struct pm4_mes_unmap_queues *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_unmap_queues));
packet->header.u32All = pm_build_pm4_header(IT_UNMAP_QUEUES,
sizeof(struct pm4_mes_unmap_queues));
packet->bitfields2.extended_engine_sel = pm_use_ext_eng(pm->dqm->dev) ?
extended_engine_sel__mes_unmap_queues__sdma0_to_7_sel :
extended_engine_sel__mes_unmap_queues__legacy_engine_sel;
packet->bitfields2.engine_sel =
engine_sel__mes_unmap_queues__compute;
if (reset)
packet->bitfields2.action =
action__mes_unmap_queues__reset_queues;
else
packet->bitfields2.action =
action__mes_unmap_queues__preempt_queues;
switch (filter) {
case KFD_UNMAP_QUEUES_FILTER_BY_PASID:
packet->bitfields2.queue_sel =
queue_sel__mes_unmap_queues__perform_request_on_pasid_queues;
packet->bitfields3a.pasid = filter_param;
break;
case KFD_UNMAP_QUEUES_FILTER_ALL_QUEUES:
packet->bitfields2.queue_sel =
queue_sel__mes_unmap_queues__unmap_all_queues;
break;
case KFD_UNMAP_QUEUES_FILTER_DYNAMIC_QUEUES:
/* in this case, we do not preempt static queues */
packet->bitfields2.queue_sel =
queue_sel__mes_unmap_queues__unmap_all_non_static_queues;
break;
default:
WARN(1, "filter %d", filter);
return -EINVAL;
}
return 0;
}
static int pm_query_status_v9(struct packet_manager *pm, uint32_t *buffer,
uint64_t fence_address, uint64_t fence_value)
{
struct pm4_mes_query_status *packet;
packet = (struct pm4_mes_query_status *)buffer;
memset(buffer, 0, sizeof(struct pm4_mes_query_status));
packet->header.u32All = pm_build_pm4_header(IT_QUERY_STATUS,
sizeof(struct pm4_mes_query_status));
packet->bitfields2.context_id = 0;
packet->bitfields2.interrupt_sel =
interrupt_sel__mes_query_status__completion_status;
packet->bitfields2.command =
command__mes_query_status__fence_only_after_write_ack;
packet->addr_hi = upper_32_bits((uint64_t)fence_address);
packet->addr_lo = lower_32_bits((uint64_t)fence_address);
packet->data_hi = upper_32_bits((uint64_t)fence_value);
packet->data_lo = lower_32_bits((uint64_t)fence_value);
return 0;
}